XTRAN — menu
- What Is XTRAN?
- What Can You Automate with
XTRAN?
- Code Assessment / Analysis
- Code Generation
- Code Transformation / Re-Engineering
- Code Translation
- Data and Text Analysis and Manipulation
- Combining XTRAN's Capabilities
- Code Quality Monitoring & Remediation
- Legacy Modernization & Migration
- Forensic Code, Data, and Text Analysis
- Interactive Query of XTRAN Code / Data / Text Mining Results
- Additional XTRAN
Applications
- How can your organization benefit
from XTRAN?
- What Computer Languages
Does XTRAN Handle?
- XTRAN
 :
Automating Code Analysis,
Re-engineering,
Translation and
Generation, and Data
and Text Analysis
and Manipulation
:
Automating Code Analysis,
Re-engineering,
Translation and
Generation, and Data
and Text Analysis
and Manipulation

- More about XTRAN
- XTRAN in the
Software Development Life Cycle

- XTRAN's
Architecture
- XTRAN's Rules
Language
- XTRAN's Pattern Matching
and Replacement Facilities
- XTRAN Data
Bases (associative arrays)
- XTRAN's Language
Parsing and Rendering Automation; XBNF
- XTRAN's Built-In
Meta-functions — functionality
- @DBG: XTRAN's
Meta-Debugger
- XTRAN
Documentation
- XTRAN
Training
- Where Did XTRAN Come
From?
- Questions or
comments?

What is XTRAN?
XTRAN is a software meta-tool we have developed that marries compiler and expert system technologies to provide the rule-driven automation of software tasks involving a wide variety of computer languages. Through manipulation of XTRAN's Internal Representation (XIR) of these languages, specified via its powerful rules language, XTRAN allows you to automate:
- Code assessment
/ analysis — both ad hoc
and production
- Code generation — either
as XIR or from
templates

- Code transformation
/ re-engineering — applying a set of
transformations to the
code
- Code translation to a different
language — either the same level, lower level
(compilation), or higher level
(decompilation)
- Code standardization — imposing coding standards and conventions
- Data analysis
and manipulation —
using XTRAN's built-in delimited list
manipulation, regular expressions, and content-addressable
data base
facility
- Text analysis and
manipulation
By meta-tool, we mean a system for rapidly creating software development automation tools. XTRAN's powerful rules language, which we call meta-code, provides an extremely productive environment in which to develop such tools. In this tool development environment, minor software tasks can be automated in minutes or hours, significant tasks in days, and major tasks in weeks.
XTRAN's rules language is not a "black art"; it can be learned and used by any competent senior software developer, and multiplies the developer's skills and talents, to accomplish much more for the effort expended.
We have already used XTRAN to create many such tools for analyzing, re-engineering, translating, and generating computer languages, analyzing data, and processing text, and many of them are provided with an XTRAN license, so you can start using XTRAN right out of the box. And your senior software developers can, after training, quickly create additional automation tools using XTRAN's rules language.
Computer languages XTRAN can manipulate include:
- Many assemblers (2GLs)
- Third generation languages (3GLs) such as C, C++, COBOL, Fortran, Java, Pascal, and PL/I
- Fourth generation languages (4GLs) such as Natural, RPG, and SAS
- Proprietary languages such as IBM's EDL and Norsk Data's NPL
- Markup languages such as HTML
- Meta-data languages such as XML
- Scripting languages
- Web languages such as Microsoft's C#
- Data base languages such as SQL
- Domain Specific languages
- XTRAN's own rules language (meta-code) — yes, XTRAN rules can analyze, modify, and even create themselves!
- Any other parsable computer language
XTRAN was invented, designed, implemented, and
documented by our President and founder,
Stephen F. Heffner. His résumé
is ![]()
![]() ,
his Curriculum
Vitæ is
,
his Curriculum
Vitæ is ![]()
![]() ,
and his
,
and his
![]() profile
is
profile
is ![]()
![]() .
.
What Can You Do with XTRAN?
XTRAN is capable of automating any software task that can be described in its powerful rules language. We divide such tasks into several broad categories:
- Code assessment /
analysis
- Code transformation /
re-engineering
- Code translation to a different
language
- Code generation (a special case of
translation)
- Data analysis and
manipulation
- Text analysis
and
manipulation
Code Assessment / Analysis
For code assessment / analysis, we configure XTRAN with one or more input language parsers but no output language renderers. XTRAN's rules language provides sophisticated analysis of any language supported by an XTRAN parser. This powerful analysis capability can also produce documentation and program descriptive information suitable for input into CASE and modeling systems. In fact, XTRAN's analysis capability, specified through its rules language, allows you to extract any information that is present in the code, at any level of detail or abstraction, and in any form that's required.
XTRAN is usually run on a single module at a time. However, its ability to persist information across runs allows the collection and reporting of system-wide information. This approach is frequently used to perform global analysis of a software system using XTRAN. We often write XTRAN analysis rules that append information from each module to a file, then digest and report the accumulated information.
Code analysis
with XTRAN can be either
production analysis, as part of the normal
Software Development Life Cycle
![]()
![]() , or ad
hoc analysis needed to address specific
issues.
, or ad
hoc analysis needed to address specific
issues.
XTRAN-automated code analysis is especially useful in assessing a body of code in terms of:
- Code quality (cyclomatic complexity, structuring, etc.)
- Modularity
- Architecture
- Calling tree
- "Include" dependencies
- Symbol usage (global, local, or both)
- Cloned code
- Dead code
- Translatability
- Portability
- Style
- Conformance to coding standards
- Code defects that can be identified using pattern matching and/or rules
- Code visualization, e.g. as HTML with color coding of statement types
- Forensic code analysis
- Anything you can think of!
Such an assessment is an important prerequisite to any software migration or modernization project.
In addition, continuous assessment of code provides to programming management the information it needs to keep software development on the right track.
![]()
![]() —
using XTRAN to automate
code analysis
—
using XTRAN to automate
code analysis
![]()
![]() —
using XTRAN to provide interactive query
of code analysis results
—
using XTRAN to provide interactive query
of code analysis results
Code Generation
For code generation, we
configure XTRAN with zero or more input language
parsers and renderers, depending on the code generation method used.
XTRAN rules can either generate code as
XIR and render it, or generate it from a template
![]()
![]() .
.
Code Transformation / Re-Engineering
For code transformation / re-engineering and standardization, we configure XTRAN with a parser and a renderer for the same language. You can then use XTRAN's powerful rules language to apply, across a body of code, any set of systematic changes that can be specified using rules. A few examples include:
- Enforce programming standards.
- Structure the code by automatically eliminating "gotos" in many cases, substituting functionally equivalent "if", "else", "for", "do", and "while" constructions.
- Find operating system dependencies and change them to a different operating system or standard library such as Posix.
- Change code to use a different API, such as a graphics library or DBMS.
- Find common low-level patterns of language usage and decompile them into higher-level constructions, thereby raising the level of the code.
- Requalify structure members to reflect changes to a structure's definition.
- Make large numbers of changes in symbol names.
Since XTRAN makes the changes to the code's XIR, which it then renders on output, the changed code is automatically restyled in terms of indentation, curly braces, line breaking, comment tabbing, etc. Since styling parameters are under user control, you can use XTRAN to restyle code as desired.
![]()
![]() —
using XTRAN to
automate re-engineering
—
using XTRAN to
automate re-engineering
Code Translation
For code translation, we configure XTRAN with one or more input language parsers and one or more output language renderers. (You can also use XTRAN's powerful code generation and re-engineering capabilities with any translation version of of XTRAN; see below for examples.)
Translation combinations we have implemented with XTRAN include:
- Encore (SEL, Gould) 32 assembly code to C
- Fortran to C and C++
- HP (Digital, Compaq) PDP-11 MACRO-11 assembly code to C
- HP (Digital, Compaq) VAX MACRO assembly code to C
- IBM PL.8 / PL.9 / PL/ix to C++
- IBM Series/1 EDL to C
- IBM Series/1 assembly code to C
- Intel PL/M to C
- Intel x86 assembly code to C
- Motorola 680x assembly code to Texas Instruments TMS370 assembly code
- NEC 78C10 assembly code to C
- Norsk Data NPL to C
- Pascal to C and C++
- PL/I to C
We have in development, or are
planning, additional translation
combinations of assemblers, 3GLs (including C, C++, COBOL, BASIC,
Fortran, RPG, Pascal, PL/I, PL/M, Ada,
and Java), 4GLs, markup languages (including HTML),
and meta-data languages (including XML).
Please ![]()
![]() for more
information.
for more
information.
With each XTRAN translation license, we deliver a standard set of translation rules for the appropriate language combination. After appropriate training, you can enhance or override those rules as needed to address issues specific to the code being translated.
![]()
![]()
![]()
![]() —
using XTRAN to
automate translation
—
using XTRAN to
automate translation
Note: We have developed the IBM Series/1 EDL and Series/1 assembly code to C versions of XTRAN in cooperation with Migration Solutions Incorporated (MSI) of Scottsdale, Arizona. MSI have developed EFL (EDL Function Library), a run-time library that supports the C code produced by XTRAN translation from EDL. MSI are also experts in the use of XTRAN to translate EDL and Series/1 assembly code. In addition to supporting translation of EDL and assembly code applications, MSI also offer an EDX emulator that can provide a quick and relatively painless way to move such applications off the Series/1 hardware.
Data and Text Analysis and Manipulation
For data and text analysis and manipulation, we configure XTRAN with only a meta-code parser, and no language renderers. You can then use XTRAN's powerful data and text manipulation capabilities. The rules language allows you to read and write text files as desired.
XTRAN's regular expression, delimited list manipulation, and content-addressable data base capabilities, along with the other capabilities of its rules language, make it an extremely powerful data and text analysis and manipulation engine.
![]()
![]() —
using XTRAN to automate data
analysis and manipulation
—
using XTRAN to automate data
analysis and manipulation
![]()
![]() —
using XTRAN to automate text
analysis and manipulation
—
using XTRAN to automate text
analysis and manipulation
![]()
![]() —
using XTRAN to provide interactive query
of data and text
analysis results
—
using XTRAN to provide interactive query
of data and text
analysis results
Combining XTRAN's Capabilities
Automating a complex software task often requires a combination of XTRAN's analysis, re-engineering, translation, code generation, and data manipulation capabilities.
![]()
![]() —
combining XTRAN's capabilities
—
combining XTRAN's capabilities
Code Quality Monitoring & Remediation
A critical part of running a successful software development operation is to maintain a high level of code quality, and adherence to the shop's coding standards and conventions. Of course, the definition of code quality varies from shop to shop, as do coding standards and conventions.
So an important property of any mechanism used to monitor code quality and remediate quality issues is flexibility — the ability to tailor the code quality analysis and remediation to the shop's definition of that quality, and to the shop's coding standards and conventions.
Monitoring code demographics and quality
A license for any code analysis version of XTRAN comes with a wide variety of rules for measuring code "demographics" and quality:
- Statements per module
- Statement type frequencies, by function or module
- Module/function cross-reference, both directions, with optional frequencies
- Function calling tree, both directions, with optional frequencies
- Include/
COPYdependency tree, both directions, with optional frequencies - Symbol cross-reference, both directions, parameterized for many different reports
- Comment density
- McCabe's Cyclomatic Complexity (a measure of logic flow complexity)
- Halstead's Volume (a measure of heterogeneity)
GOTOcount- Knots (
GOTOcrossings) - "Exit" statement count
- Extent, frequency, and distribution of code nesting depth
- Straight-line code run length by nesting level
- Dead code
- Cloned (copy/paste) code
You can use all of these rules that come with XTRAN "as is", or you can adapt them to your shop's definition of code quality and to your coding standards and conventions. And, after training, you can create XTRAN rules to add your own code demographics and quality analysis automation, working exactly the way you want it to.
We recommend that you inject such code quality and standards adherence
analysis into the Software Development Life Cycle as early as
possible — at the point where the developer has a clean compile of
new or changed code and is ready to submit it to a build for
testing. ![]()
![]() If it gets
a passing grade, on it goes; if not, back it goes to the developer while it's
still fresh in his/her mind.
If it gets
a passing grade, on it goes; if not, back it goes to the developer while it's
still fresh in his/her mind.
The code quality analysis should cover 3 main issues:
- Code defects discoverable (or potentially implied) through static analysis.
- Code quality, using whatever measures the development manager believes are best. The code analysis tool obviously must be flexible enough to accommodate the manager's preferences.
- Adherence to the shop's coding standards and conventions. This requires that the code analysis tool be flexible enough to accommodate them.
We know that the earlier a code defect is caught, the less it costs to fix and the less damage it does; this approach detects as many defects as possible, as early as possible.
The quality analysis process can send any negative results back to the developer while the code is fresh in his/her mind, and can also notify the development manager of the developer's performance on such tests so the manager can monitor the developers and catch problem trends early.
XTRAN provides the combination of code analysis
power and flexibility to automate the code quality program
described above.
![]()
![]()
![]()
![]()
![]()
![]() —
using XTRAN to provide interactive query
of code quality analysis results
—
using XTRAN to provide interactive query
of code quality analysis results
Automating code quality remediation
Of course, if you monitor code quality continuously using XTRAN, as shown above, remediating it is never necessary. But there are situations where it is. For instance:
- You have acquired code through a merger or acquisition, and it doesn't meet your code quality standards, nor your coding conventions.
- As a software services firm, you have agreed to assume development and maintenance responsibilities for a customer's code, and you have agreed with them on a new set of code quality standards and coding conventions.
- You have been hired as the new software development manager, and you are imposing code quality standards and coding conventions on the body of code for which you are now responsible.
A license for any re-engineering or translation version of XTRAN comes with a wide variety of rules for automating the remediation of code quality issues:
- Structure code — eliminate
gotos by imposingif/else,for,while, anddoconstructs - Eliminate additional
gotos by "unrolling" them, using local procedures to avoid code duplication - Combine low-level expressions to a higher, more readable and maintainable level
- Eliminate unneeded code block constructs
- "Flatten" deeply-nested code to a more readable and maintainable form by extracting deep code levels as local procedures
- Convert lengthy
if/elsechains toswitch/caseconstructs - Eliminate numbered
gotos andgoto <label> - Delete dead code
You can use all of these rules that come with XTRAN
"as is", or you can adapt them to your shop's definition of
code quality and to your coding standards and conventions. And,
after training, you can create XTRAN rules to
add your own code quality remediation automation, working exactly the
way you want it to.
![]()
![]()
![]()
![]()
Legacy Modernization & Migration
Many existing legacy software systems represent major investments that must be modernized and/or migrated in order to provide the agility required to remain competitive:
- Unlock the code from a platform and/or language that is proprietary or approaching end of life.
- Allow the use of modern software development tools, to increase the productivity of the software development department.
- Attract and keep the best architects and developers.
- Improve the quality of the code, to reduce maintenance costs and allow timely enhancements of the system.
- Move the code to an Object-Oriented language, explicating latent OO in the process.
- Rationalize disparate systems, to make them work together better and to provide a common software language and platform.
- Prepare systems for transition to a Service Oriented Architecture (SOA), and automate that transition.
The best modernization and/or migration strategy will likely involve one or more of the following alternatives:
- Re-engineer (and possibly translate) the existing code, to improve its quality, repurpose it, rearchitect it for modern use, and/or re-host it onto a newer platform.
- Replace the code with commercial off-the-shelf software ("COTS").
- Totally reimplement the application from the ground up.
When it comes time to modernize and/or migrate your legacy applications, XTRAN can play a vital role in automating virtually every aspect of the process. Achieving a high level of software development automation is critical to the success of the project, to reduce the number of bugs introduced, and ultimately, to reduce the risk of failure.
- Automated Code analysis
- Verify the accuracy of an existing functional specification against the code, or, in the worst case, extract such a specification from the code itself. Such a specification is required in order to determine the best modernization and/or migration strategy, and then implement that strategy.
- Determine the quality of the legacy code, to decide if it is worth saving, and assess the need for quality improvement prior to modernization or migration.
- Find and extract business rules from the code. If you decide to replace the application with COTS or to totally reimplement it, you must know what business rules to implement in the replacement. If you decide to re-engineer, you will need to know what the business rules are and where they are, so they can be exposed as services to be reused.
- Assess the impact of a legacy modernization project on the code body to be modernized. For example, if you anticipate a change to a DBMS or other third-party product, all calls to that API may have to be changed. Analysis with XTRAN can find and catalog information about all such calls, and assist in determining the best strategy for automating the changes.
- Assess the impact of a port on the code body to be ported. For example, all operating system dependencies may have to be changed. Analysis with XTRAN can find and catalog information about all such dependencies, and assist in determining the best strategy for automating the changes.
- Assess the quality and adherence to coding standards of the re-engineered or ported code, on an ongoing basis.
- Answer specific questions about what's in the code, on an ad hoc basis.
- Automated Code Transformation /
Re-engineering
- Improve the quality and maintainability of the code, and raise its level, prior to modernization. This can significantly reduce the negative impact of a modernization effort, as well as improving the quality of the result.
- Expose the business rules in the code as services to be reused. This can include extracting such rules as components.
- Implement an API change, for example a change to a different DBMS or other third-party software product. This can involve changing every call to the product's API; XTRAN rules for automating such changes can actually take advantage of the API usage information catalogued during the analysis phase.
- Implement specific changes to the code, on an ad hoc basis.
- Move disparate systems to a common platform, for easier maintenance and sharing of skills and code.
- Automated Code
Translation
- Move legacy code from a proprietary language to an open language, in order to reduce dependence on a specific vendor.
- Move legacy code from an obsolete language, for which it is increasingly difficult to find experienced programmers and modern development tools, to a modern language for which programmers and modern tools are available.
- Move legacy code from a non-portable language to a portable language, in order to move the application from an older platform, with high price/performance and increasingly higher maintenance costs and difficulty, to a modern, cost-effective platform with lower price/performance and lower maintenance costs.
- Move disparate systems to a common language, for easier maintenance and sharing of skills, tools, and code.
Code
modernization ![]()
![]()
![]()
![]()
Code
migration ![]()
![]()
![]()
![]()
Forensic Code, Data, and Text Analysis
In civil and criminal legal proceedings involving computer code, computerized data, or text, it is sometimes necessary to analyze them to determine their implications for the legal case. XTRAN's powerful code analysis, data analysis, and text manipulation capabilities are ideal for this, and can be "tuned" to specific requirements using XTRAN's rules language.
Similarly, Information Security ("InfoSec") activities often require such analysis, to look for vulnerabilities in code such as "back doors" and the notorious "buffer overflow" code defect.
One problem commonly encountered with such analysis is the sheer bulk of code, data, or text that must be analyzed, often within a limited amount of time (sometimes dictated by a court). XTRAN provides the automation needed to reduce this problem to manageable proportions, making it possible to meet deadlines, as well as increasing accuracy and saving both time and money.
Forensic code
analysis ![]()
![]() may
involve:
may
involve:
- Analyzing the
code's architecture
. XTRAN can provide this, at
any level of abstraction or detail.
- Determining the
code's quality .
XTRAN provides a number of popular quality
measures, and others can be added as needed. This can also
involve looking for code defects that can be found through code
analysis.
- Comparing two bodies of code to determine if one was copied from the other. XTRAN provides powerful code comparison capabilities, which can be "tuned" to any level of detail.
- Determining whether the code satisfies contractual requirements. XTRAN can be "tuned" to search the code for constructs that imply either satisfaction of, or failure to satisfy, such requirements.
- Determining whether contractually required documentation accurately describes the code. XTRAN can be "tuned" to search for constructs that verify, or fail to verify, the accuracy of the documentation.
- Determining whether the code contains any "back doors", "trap doors", or "bombs". XTRAN's pattern matching facilities can be used to look for common patterns that imply such problems in the code.
- Searching for the occurrence of patterns in the code that are forensically interesting.
Forensic analysis of computerized data may involve:
- Analyzing the data for the occurrence of specific values, or combinations of values, in specific fields.
- Extracting occurrence counts, frequency distributions,
Markov analysis , and
other statistical measures from the data.
- Searching for the occurrence of patterns in the data that are forensically interesting.
Forensic analysis of text may involve:
- Analyzing the text for the occurrence of specific words or phrases.
- Extracting occurrence
counts , frequency distributions, or Markov
analysis of such
words or phrases that bear on the case.
- Analyzing proximity of significant words or phrases to each other.
- Categorizing and sorting large numbers of documents based on their contents.
- Tracing citation trails among a group of documents.
- Searching for the occurrence of patterns in the text that are forensically interesting.
- Analyzing potential forgery based on analysis of writing styles and use of idioms.
- Searching for potential plagiarism.
Stephen F. Heffner, XTRAN's author, is himself an Expert Witness, with report, deposition, and trial testimony experience. He has used XTRAN's forensic analysis capabilities in support of his Expert Witness activities.
![]()
![]() —
using XTRAN to automate word and phrase
usage analysis in unstructured text
—
using XTRAN to automate word and phrase
usage analysis in unstructured text
![]()
![]() —
using XTRAN to provide interactive query
of forensic analysis results
—
using XTRAN to provide interactive query
of forensic analysis results
Additional XTRAN Applications
XTRAN's capabilities are applicable to a wide variety of additional problems, including Euro, code dialect translations, CASE tool interfaces, verification and enforcement of coding standards and styles, programming training and tutoring, and other rule-driven manipulation of computer languages, data, and text.
Ultimately, the only limit to the ways you can use XTRAN is your imagination.
How can your organization benefit from XTRAN?
The following XTRAN capabilities are available to all organizations with responsibility for a significant amount of code, data, and/or text. Note that all of these capabilities are realized using XTRAN's rules language. XTRAN rule sets already exist for many of these examples, and are delivered with XTRAN as appropriate. They can be enhanced and adapted by your senior systems programmers (after training), who can also create new rules as needed.
- Automate code analysis —
examples:
- Monitor code quality (by your definition)
and demographics
- Extract and report code dependencies,
including function calling tree, include/COPY tree,
and data
dependencies
- Locate and quantify dead code
- Locate and quantify cloned code
- Monitor adherence to coding standards and conventions
- Assess impact of changes to APIs
- Report offsets and sizes of structures
and unions and
their members
- Verify existing functional specifications against
the code, or reverse engineer functional specifications
from it
- Extract and report code's data and execution
architecture
- Extract and format documentation carried in the code's comments
- Analyze and report state transitions at any
level (Markov
analysis)
- Detect and report potential bugs based on code patterns
- Display code with filters and/or colorization,
to highlight code properties of
interest
- Ad hoc analyses as needed
- Monitor code quality (by your definition)
and demographics
- Automate code transformation
and re-engineering
— examples:
- Improve code
quality:
- Structure to remove
gotos by imposingif/else,for,do, andwhile
- Decompile low-level constructs to higher-level
ones
- Declone code
- Remove dead
code
- Refactor deeply nested code to reduce nesting
- Add documentation based on analysis of
the code
- Structure to remove
- Retrofit preprocessor definitions and the include/COPY
files that declare
them
- Impose coding standards and conventions on inherited or acquired code
- Impose API changes on all relevant function calls
- Impose data structure changes on all structure/union member references
- Consolidate inherited or acquired IT assets to common
hardware and/or operating
system
- Obfuscate/deobfuscate source code for security
- Prepare included files for multiple
inclusions
- Ad hoc transformations as needed
- Improve code
quality:
- Automate code translation
and generation —
examples:
- From lower-level to higher-level
(decompilation), such as assembly code
to 3GL ,
or 3GL to 4GL
- From obsolete language to modern one
- From proprietary language to portable one
- Consolidate inherited or acquired IT assets to common language
- Compile Domain Specific and special purpose languages to lower level languages
- Index and cross-link documents in markup languages
such as HTML
- Move code from one dialect to another, or eliminate dialect dependencies
- From lower-level to higher-level
(decompilation), such as assembly code
to 3GL
- Automate analysis and
manipulation of
data and
text — examples:
- Delimited list manipulation (such as CSV
data)
- Regular expressions, including group matching and replacement
- Analyze and report state
transitions (Markov
analysis)
- Built-in data base facility for storing intermediate results
- Delimited list manipulation (such as CSV
data)
Computer manufacturer:
- XTRAN capabilities shown above, for your code
- Presale — automate code analysis needed
to assess impact of moving customer to your
hardware, operating system, languages,
and/or APIs
- Automate re-engineering and/or translation needed
to help customers move applications to your
hardware, operating system, languages,
and/or APIs
- Provide code analysis & re-engineering "black boxes" for your languages
Independent software vendor (ISV):
- XTRAN capabilities shown above, for your code
- Presale — automate code analysis needed
to assess impact of moving customer to your operating
system, languages,
and/or APIs
- Automate re-engineering and/or translation needed
to help customers move applications to your operating
system, languages, and/or APIs
- Provide code analysis & re-engineering "black boxes" for your languages
Software services / outsource vendor:
- Presale — automate code analysis needed to quote
assuming responsibility for your customer's code,
including code quality
assessment
- XTRAN capabilities shown above, for your customer's code
Enterprise architecture / IT consultant:
- XTRAN capabilities shown above, for your clients' portfolio management, system architecture, and software development
- Awareness of automation trends in software development
Expert Witness / forensic analyst / law enforcement:
IT department:
- XTRAN capabilities shown above, for your code
What Computer Languages Does XTRAN Handle?
XTRAN currently accommodates a wide variety of computer languages, including:
- Assemblers (2GLs)
- Encore (SEL, Gould)
32
- HP (Digital, Compaq) PDP-11
MACRO-11
- HP (Digital, Compaq) VAX
MACRO
- IBM mainframe (360, 370, system/Z)
- IBM Series/1
- Intel x86
- Motorola 680x
- NEC 78C10
- Texas Instruments TMS370
- Encore (SEL, Gould)
32
- 3rd generation languages (3GLs)
- C, including K&R and ANSI
dialects
- C++
- COBOL
- Fortran, including IBM, Mark III, and VMS
dialects
- Java
- Pascal, including HP (Apollo) Domain, IBM, Microsoft, OmegaSoft,
and VMS
dialects
- PL/I, including IBM and VMS
dialects
- C, including K&R and ANSI
dialects
- 4th generation languages (4GLs)
- Adabas
Natural
- RPG
- SAS
- Adabas
Natural
- Proprietary languages
- IBM Series/1
EDL
- IBM PL.8 / PL.9 /
PL/ix
- Intel
PL/M
- Microsoft
C#
- Norsk Data NPL
- IBM Series/1
EDL
- Markup languages
- HTML
- HTML
- Meta-data languages
- XML
- XML
- XTRAN's own rules
language (meta-code)
XTRAN's modular and language-independent
architecture, and its
automated language parsing and rendering
technologies, make it easy to add new languages. We
have additional languages in development; if you don't see your
language, please ![]()
![]() .
.
XTRAN's Architecture
XTRAN consists of:
- A powerful and sophisticated rules language, which we call meta-language or meta-code because it is used to define and manipulate other languages.
- A language-independent inference engine for evaluating rules written in meta-code.
- Language-specific parsers that read computer language text files and convert them to:
- A proprietary XTRAN Internal Representation (XIR) that XTRAN uses to represent all computer languages (including meta-code) during its processing, and which meta-code manipulates as data (and yes, that means it can manipulate itself).
- Language-specific renderers that render and output XIR as computer language text files.
Here's a graphical look at XTRAN's code and data architecture:
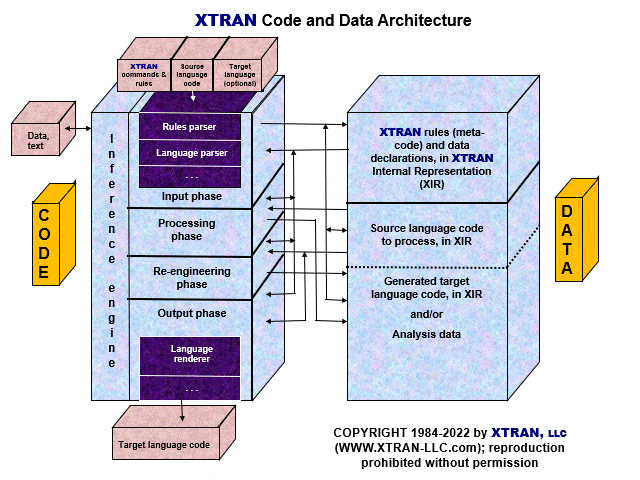
The left side represents XTRAN's code, and reflects the sequence of phases XTRAN executes when it runs. The right side represents the data that XTRAN keeps in memory as it runs. The arrows indicate the production and consumption of XIR by XTRAN's various execution phases.
The purple parts of XTRAN's code (language parsers and renderers) are language-specific; the remainder of the code, as well as XTRAN's own rules language, is language-independent.
This unique architecture means that a new language (or language combination) requires only the development of a parser and/or a renderer, plus existing or new rules, in order to apply the power of XTRAN to a new language manipulation problem.
XTRAN organizes all of its XIR in code trees. XTRAN has many built-in code trees; you can also create your own. For instance, you can write a rule that creates an empty code tree, parses a code source file to it, manipulates the code as XIR, renders the result to an updated code file, and deletes the code tree — all in one rule!
Internally, XTRAN is highly object-oriented. "Computer language" is a data class, as are "parser" and "renderer". XTRAN can be configured with multiple parsers and/or renderers as needed, to handle a mixture of input and/or output languages. (XTRAN is always configured with at least a parser for its own rules language.)
XTRAN's Rules Language (meta-code)
XTRAN's powerful rules language (which we call meta-language or meta-code) is an evaluated, interpretive language. Its syntax is like C, but its semantics are more like Lisp. In terms of style, it's a mostly functional language, with some procedural elements. It includes meta-statements, meta-expressions, meta-variables, meta-functions, and meta-comments.
Interpretive evaluation of meta-code is so fast that it allows processing of very large amounts of code in reasonable time. For example, we performed substantial analysis and re-engineering, involving intensive XTRAN rules evaluation, on 600,000+ code lines of PL/I in just over four hours on a laptop computer.
The many capabilities offered by XTRAN through its rules language include:
- Data types — Integer, real, text, file, expression, and statement. The last two refer to values consisting of expressions or statements represented in XTRAN Internal Representation (XIR).
- Extensive facilities for controlling rule evaluation timing (early vs. late binding), in terms of XTRAN's phased operation, including the ability to pass unevaluated meta-code around and to selectively force, or protect from, evaluation at the expression and subexpression levels.
- More than 450 built-in meta-functions for manipulating XIR of computer languages and other data, and for affecting XTRAN's state. Each calling argument can be any meta-expression that evaluates to the appropriate data type.
- Built-in meta-functions include a full set of operator meta-functions, including equivalents to all of C's operators, and n-ary forms of some operators that are binary in "in-fixed operator" languages.
- The ability to extend XTRAN's rules language by creating user meta-functions, written in meta-code, with data-typed parameters. Such user meta-functions are invoked exactly the same as built-in meta-functions. User meta-functions can have local variables, and can be recursive.
- Iterator meta-statements ("for", "while", "do") and alternator meta-statements ("if", "else"), to control the results of evaluation.
- Recursive iterators, as part of the rules language, that visit each XIR element (statement, expression, symbol, etc.) once and apply specified rules to it. This allows you to concentrate on the job at hand, instead of worrying about recursively traversing the code you're manipulating.
- Navigation that allows you, from a particular XIR meta-entity (statement, expression, etc.), to access and possibly change the context in which it occurs, all the way out to the full body of code currently being processed and at every level of detail. Both absolute and relative navigation are available.
- Text manipulation facilities, including extensive facilities for
manipulating delimited lists such as comma-separated
values.
- The text formatting facilities of C's
printf()andscanf()functions. - Regular expressions for manipulating text, including "egrep" grouping facilities. You can capture a copy of the text that matched each group, if desired.
- File I/O for creating, appending to, reading, and writing text files.
- Terminal I/O for communicating with the user at run-time, via
stdinandstderr. - Built-in facilities for interactive graphical browsing and exploration of every detail of XIR, including full hypertext browsing capabilities and visible "bread crumbs".
- A built-in data base facility that
provides in-memory, n-dimensional, content-addressable data bases
(associative arrays) for storing XIR and data. This
facility is extremely useful for organizing code fragments
and information, both when analyzing code and
when transforming it.
- Powerful XIR pattern matching
and replacement facilities, at the statement
and expression levels.
- The ability to compare the XIR of two sets of code, with extensive control over what XIR entities are compared and how. For example, you could choose to exclude comments from the comparison. By choosing which entities to exclude, the comparison can be as abstract or detailed as desired. As with XTRAN's pattern matching facilities, comparison of XIR is totally independent of physical aspects of the code such as line breaks, indentation, and comment tabbing.
- The ability to move computer languages (including meta-code) between the symbolic domain (XIR) and the text domain (source code), in both directions, dynamically; in other words, incremental, fully dynamic parsing and rendering. This allows computer languages to be manipulated in both their symbolic (XIR) form and their text form. It also allows rules to write more rules, then parse and evaluate them.
- The ability to embed meta-code in any host language, at both statement and expression levels, and to embed host languages in meta-code.
- Full access to XIR from rules, allowing you to explore the XIR form of code being processed, including its meta-data, to any level of detail.
- Code rendering decorations, which are text
strings XTRAN inserts in the output at code
rendering time:
- At start of output
- Before and/or after each statement of a given language, based on a condition
- Before and/or after each expression of a given language, based on a condition
- At end of output
Such decorations could, for example, be HTML tags to emphasize or color statements or expressions based on conditions you specify.
- Unconditional code decorations, which are text strings
an XTRAN rule can add to a statement
or expression in XIR, and which
XTRAN's rendering engine then renders:
- Before the statement or expression is rendered
- After the statement or expression is rendered; for a statement, either before or after its child statements (if any) are rendered
Such decorations could, for example, be HTML tags to link statements.
- Statement output filtering, by language
— XTRAN renders only those statements that
meet at least one of a series of conditions. This is a good
way to restrict XTRAN's rendered output to just
what you are interested
in.
- @DBG, a powerful, built-in meta-debugger for debugging XTRAN rules.
We have created many XTRAN rule sets that automate a wide variety of analysis, re-engineering, and translation tasks. We provide these rules, as appropriate, with each XTRAN license, so you can be productive with XTRAN right out of the box. And, after appropriate training, you can create additional rules to automate both production and ad hoc software tasks.
Note that XTRAN's rules language is proprietary
to XTRAN, LLC; access
to it requires an XTRAN license or
a Nondisclosure Agreement. Please
![]()
![]() for more
information.
for more
information.
XTRAN's Pattern Matching and Replacement Facilities
XTRAN provides, via its rules language, an extremely powerful suite of pattern matching and replacement facilities you can apply to code content (in the form of XIR), at both the statement and expression levels:
- You can specify a pattern in a host language, in meta-code, or in a combination of both.
- Any element of a pattern can be "wild".
- You can optionally qualify each such "wild" element using an arbitrarily complex condition comprising additional meta-code to be evaluated for each match attempt. Such a condition can, through navigation, explore the context in which the match is being attempted.
- XTRAN will, if requested, capture a copy of what matched a "wild" element, at match time.
- Such a copy can then be reported, referenced later in the same pattern, or reused in a replacement pattern.
- Since pattern matching is done on XIR, it is totally independent of physical aspects of the code such as line breaks, indentation, and comment tabbing. And, of course, when XTRAN renders the result as text code, it will automatically restyle and indent the updated code properly.
![]() that
use XTRAN's pattern matching and replacement
facilities to automate restructuring of code
and elimination of "goto"s:
that
use XTRAN's pattern matching and replacement
facilities to automate restructuring of code
and elimination of "goto"s:
XTRAN Data Bases (associative arrays)
An XTRAN in-memory data base is an n-space (with unlimited n) in which each cell is addressed using zero or more subscripts. Effectively, each data base is a multi-dimensional associative array. Each subscript can be either
- Missing (elided)
- An integer
- A text string — making the data base content-addressable
Each data base cell can contain zero or more values, with each value being a legal XTRAN meta-expression:
- An integer value
- A real value
- A text value
- A pointer to an open file
- A meta-expression, as XIR
- A host-language expression, as XIR
- A text string naming a statement meta-variable, effectively storing a pointer to that meta-variable's value — one or more statements as XIR
Because an XTRAN data base is implemented as a sparse matrix, it can accommodate large quantities of data and still provide quick retrieval response.
XTRAN's rules language includes a full set of built-in meta-functions for creating and manipulating such data bases.
XTRAN's data base facility is extremely useful for organizing code fragments and information, both when analyzing code, data, and text, and when transforming them.
![]()
![]() and
and ![]()
![]() that
demonstrate the use of XTRAN data
bases
that
demonstrate the use of XTRAN data
bases
XTRAN's Language Parsing and Rendering Automation; XBNF
An XTRAN language parser performs the task of reading a computer language's text source code and creating the XTRAN Internal Representation (XIR) that represents that code. XTRAN's parsing engine allows construction of a parser in XTRAN's rules language (meta-code) by describing the grammar to be parsed, using a user-friendly form of Extended Backus-Naur Form (EBNF) that we call XTRAN BNF (XBNF). XBNF, as used for parsing, references a small number of hard-coded parsing primitives, and allows recursive productions. You can construct additional parsing primitives in meta-code using XBNF. XTRAN provides a parsing XBNF trace facility that shows, in XTRAN's run log, each XBNF entity tried, against what text it was tried, and whether it succeeded or failed.
Similarly, an XTRAN language renderer performs the task of rendering a computer language's XIR as source code text and putting it out, including all of the code styling issues that implies. XTRAN's language rendering engine allows construction of a renderer in meta-code by describing the grammar to be output, using a rendering version of XBNF. XBNF, as used for rendering, references a small number of hard-coded rendering primitives, and allows recursive productions. You can construct additional rendering primitives in meta-code using XBNF.
XBNF includes facilities for parsing and rendering:
- Nonpositional (free-format) languages, such as C and PL/I
- Positional (column-oriented) languages, such as RPG, job control languages, and some assemblers
- Languages that are a mixture of positional and nonpositional, such as COBOL
XTRAN's parsing and rendering engines provide fully integrated dialect control, allowing a parser's or renderer's XBNF to be conditioned on the language dialect being parsed or rendered. This dialect control is dynamic, allowing you to switch dialects during parsing or rendering if needed.
Unlike "compiler compilers" such as LEX/FLEX+YACC/Bison and ANTLR, which generate code for parsers as their output, XTRAN executes XBNF dynamically at language parsing or rendering time, including a "fastback" parsing feature. This also means that XTRAN parsing and rendering are fully incremental. For instance, you can write a single XTRAN rule that renders an XIR entity as text, manipulates that text, and parses the result back into XIR.
XBNF is integrated with meta-code, so a language parser or renderer can be written to be "tuned" with additional rules, dynamically if appropriate.
For historical reasons, some of XTRAN's older language parsers and renderers are hard-coded. However, they can be enhanced and/or overridden using parsing or rendering XBNF.
XTRAN's Built-In Meta-functions — Functionality
XTRAN's rules language comes with over 450 built-in meta-functions that provide ready-to-go functionality, in the following functional areas:
- Meta-variable and meta-function declaration and manipulation
- Meta-operators -- arithmetic, comparison, logical, bitwise, shift, conditional
- Text manipulation
- Delimited text list manipulation
- Delayed evaluation control
- XIR code tree manipulation
- Navigation in XIR
- Parsing control
- Rendering control
- Dynamic, incremental parsing and rendering
- In-memory, content-addressable data bases
- Meta I/O — terminal, text files
- Processing control
- Re-engineering and translation control
- XIR pattern matching & replacement — insensitive to code style etc.
- XIR comparison (tunable) — also insensitive to code style etc.
- XIR graphical browsing
- Access to XIR from rules
- @DBG — XTRAN's meta-debugger
You can also create your own user meta-functions, written in meta-code, that are specific to your needs.
@DBG — XTRAN's Meta-Debugger
XTRAN includes a powerful, full-featured, interactive meta-debugger, called @DBG, which allows you to control XTRAN's execution and debug your meta-code. @DBG's many features include:
- Breaks to @DBG on any of:
- Reference to a specified source or target statement, optionally limited to one or more specified XTRAN processing phases (parse, process, etc.)
- Evaluation of a specified meta-statement
- Occurrence of a specified event
- Start of a specified XTRAN processing phase
- Reference to a specified symbol
- Parse of a specified atom
- Attempt to parse a specified XBNF text element
- Attempt and/or success of a specified statement pattern match/replacement
- Evaluation of XTRAN's built-in "break to @DBG" meta-function anywhere in the rules being evaluated, with optional conditionalization of the break and @DBG commands to be executed
- Break actions (@DBG commands to execute at time of break)
- Meta-variable value change watchpoints, with optional action such as a break to @DBG
- Meta-function call traceback
- Stepping of meta-code evaluation: Over, into, and out of user meta-functions; to a specified meta-statement
- Dynamic meta-code evaluation at @DBG command level
- Command history
- Invocation of XTRAN's graphical, interactive XIR browsing mode
- Indirect @DBG command files
Many of these features are also accessible via XTRAN's command line flags or built-in meta-functions.
XTRAN Documentation
When we license and deliver XTRAN, we provide with it a variant of the XTRAN User's Manual appropriate to the licensed activity and computer languages. The XTRAN User's Manual comprises about 50,000 lines of HTML, organized into more than 60 chapters. It provides a thorough reference to XTRAN, with many usage examples.
Since HTML is one of the computer
languages XTRAN
can analyze, re-engineer, translate,
and generate, we use XTRAN
to cross link (Wikipedia-style) and index its
own XTRAN User's Manual, and to
produce variants that match licensed XTRAN
activities. ![]()
![]() and
description of that process
and
description of that process
We also use TemplaGen, a template-driven artifact generator implemented in XTRAN's rules language, to automate the generation of substantial parts of the XTRAN User's Manual, as well as significant parts of XTRAN's own code.
So XTRAN is automating itself!
We also provide, with XTRAN, a large number of stand-alone examples appropriate to licensed XTRAN activities, including actual XTRAN rules, input, and output.
Note that the XTRAN
User's Manual and XTRAN examples
are proprietary to XTRAN,
LLC; access to them requires
an XTRAN license or a Nondisclosure
Agreement.
Please ![]()
![]() for more
information.
for more
information.
Where did XTRAN Come From?
In 1983, we needed to port one of our products, XFORM, from the Digital VAX computer to the PC. XFORM was originally written in Digital PDP-11 assembly code, but we had previously translated it to VAX assembly code, creating our CONPAX translation tool to automate that process. (CONPAX was so successful in-house that we took it to market, and it helped over forty licensees translate millions of lines of assembly code.) So the requirement was to translate the VAX assembly code into C.
Our Founder and President, Stephen F. Heffner, hand-translated XFORM's VAX assembly code to C. He observed that this process was very tedious and mechanical. However, at the same time, it required significant judgment and the application of sophisticated rules. Since we had already created one tool for automatic translation, he began to think about how this more demanding type of translation could be automated.
In 1984, one of our large multinational clients had a problem — a large body of Digital PDP-11 assembly code needed to be ported to a more modern computer. However, the code had been worked on by many programmers over a long period of time, and was not very well documented, either internally or externally.
They decided that, before they could port the code, they needed to fully understand what it did; in other words, they needed to create an accurate functional specification for it. The problem was that they had very few PDP-11 assembly programmers left by then, and the few they had were heavily committed. So they thought that, if they could somehow get the PDP-11 assembly code into C with equivalent functionality, they could put some of their C programmers to work figuring out and documenting the code.
Since they were using our XFORM product, and had previously used our CONPAX translation tool to port some of their other PDP-11 assembly code to VAX assembly code, they thought of us, and came to us with a question: Did we think it would be possible to automate the translation of PDP-11 assembly code to C? Because of our experience with CONPAX, and our recent experience in translating assembly code to C by hand, our answer was yes — we thought that was feasible.
Our client then issued an RFP for a feasibility study to us and four other firms, primarily compiler vendors. We and two other vendors responded with bids, and our client funded all three of us.
Our two competitors submitted papers discussing how they would approach the problem. Instead of a paper, we submitted a prototype of XTRAN, as a proof of concept, and successfully demonstrated the automation of assembly code translation to C using a rules-based approach.
Our client then funded us to create a full production version
of XTRAN. They got an unlimited license to it,
but we kept full ownership of the product. With help from us, they
used XTRAN to translate their PDP-11 assembly code to
C. Although their original intention was to
use XTRAN only as a reverse engineering tool, the
resulting C code was good enough that they actually used it for the
port. ![]()
![]()
Since that time, XTRAN has grown tremendously in both language coverage and overall capabilities. It now comprises more than one-half million code lines of extremely high quality, extremely sophisticated, thoroughly documented, and highly portable C code. However, as a testament to the robustness of XTRAN's original design and XTRAN Internal Representation (XIR), they both survive to this day, essentially in their original form.