TemplaGen — Automate Generation of Artifacts from Data
Menu
- Introduction to TemplaGen
- Process Flowchart
- Typical TemplaGen Use Cases
- Scenario 1 — Election official maintaining voter registration data and analyzing election results
- Scenario 2 — Anti-terrorism or plagiarism analyst looking for common authorship
- Scenario 3 — Political candidate wanting to do a targeted mailing to constituents
- Scenario 4 — Master Data Manager
- Scenario 5 — Data Engineer doing data transformation and cleanup
- Scenario 6 — Webmaster
- Scenario 7 — Software architect
- Scenario 8 — DevOps Engineer
- Scenario 9 — Robotic Process Automation (RPA) Engineer
- Scenario 10 — Data Scientist working with Big Data, Machine Learning, and Artificial Intelligence
- Scenario 11 — XTRAN Knowledge Engineer capturing software engineering expertise in XTRAN's rules language
- Scenario 12 — Software Engineer maintaining, documenting, and testing an API
- Scenario 13 — TemplaGen librarian maintaining your enterprise's TemplaGen templates
- In-House Use (a.k.a. eating our own dog food)
- How to Automate Software Engineering with TemplaGen
- TemplaGen Examples
- Data file used for examples 1-4
- Example 1 — Generate an HTML table
- Example 2 — Generate a C array of structures
- Example 3 — Generate a text document
- Example 4 — Data selection and transformation
- Example 5 — Use regular expressions to embed HTML markup in normal text
- Example 6 — Combine data from multiple sources
- Example 7 — Generate "make" files for DevOps
- Example 8 — Generate multiple artifacts from multiple data sources
- Example 9 — Format block comments in generated code
- Example 10 — Look for common authorship based on word and phrase analysis
- Example 11 — Create a script to search all TemplaGen templates for a text pattern
- Example 12 — Error-check DSV data
- Example 13 — Select data using sophisticated criteria
- Example 14 — Continue an interrupted TemplaGen run
Introduction to TemplaGen
TemplaGen is a no-code / low-code data utility that automates the template-driven generation of artifacts from data.
TemplaGen instantiates one or more output artifacts from a text template, optionally using data from one or more delimiter separated value (DSV) data files. (The most common form of DSV is comma separated values, or CSV.) Such a data file might, for instance, be generated from a repository or exported from a spreadsheet.
TemplaGen is implemented in the rules language ("meta-code") of XTRAN, our Expert System for automating the manipulation of computer languages, data, and text. The original XTRAN rules took 1¾ hours to design, 4¾ hours to create, and 3¾ hours to debug. (That's right, only 10¼ hours total!) We have since added many features, but TemplaGen is still less than 5,000 code lines of XTRAN rules.
A TemplaGen template consists of TemplaGen commands, to tell TemplaGen what we want it to do, and lines to be instantiated in the target artifact.
TemplaGen's capabilities are powerful enough to automate the generation of fully readable, maintainable, well-styled artifacts — computer code (for both production and testing), XTRAN rules, Web content, XML, documentation, scripts, test data, emails, processed DSV data, DevOps artifacts, reports, etc.
TemplaGen normally assumes that the first non-comment line in a data file is a DSV line of field labels, which are then used in templates to identify field positions in the DSV data lines that follow the field labels line. This is a common convention used with DSV data, especially when exported from a data base or spreadsheet. However, for data files with no label row, we can specify the field labels in the template — either directly or via an environment variable setting.
TemplaGen provides the following features:
- It accommodates multiple DSV data input files, and can generate multiple output artifacts, using a single template. This can be critical when processing very large data sets, for instance as input to or output from Big Data, Artificial Intelligence, and Machine Learning runs, to minimize the number of data set traversals.
- It allows comments in a template. This allows us to document our templates internally. One application of this capability is to add meta-data describing any artifact we are using TemplaGen to generate.
- It also allows comments in a data file. This allows us to document our data files internally, and to add meta-data to them.
- It honors environment variable names embedded in the template, by replacing them with the named environment variables' values; a template can also set them. This allows us to customize a template instantiation by setting environment variable values before running TemplaGen, typically in a script that runs it.
- It provides TemplaGen variables that a template can set, and honors those names embedded in the template, by replacing them with the named variables' values (as with embedded environment variable names). This allows us to selectively override environment variable values when running TemplaGen, as well as using computed results in our template.
- It provides memory-resident associative arrays, which can be subscripted not only with integers, but also with text strings, providing keyed random access to data. They can scale to hold very large amounts of data while still providing rapid access to the data. Such arrays are convenient for organizing data for the template's use, such as the contents of a reference data base.
- It provides the convenient loading of such associative arrays from DSV data files, typically exported from a data repository.
- It allows the use of what we call a DSV expression — an expression that operates on current DSV data field values if any and TemplaGen or environment variable values, using a broad range of operators that provide Boolean logic, arithmetic, bit operations, text manipulation including regular expression (pattern) matching and replacement, and text formatting.
- It allows conditioning the processing of template lines (repeated or not) with if / elseif / else commands, based on DSV expressions. Such conditionalizations can be nested, with no limit on the depth.
- It provides built-in escapes for special characters that can be used to encode them in a template (or in data), to avoid problems with them. They are unescaped just before each instantiated template line is written out.
- It provides for the repetition of a series of template lines
with repeat / continue / break commands:
- One repetition for each data line read from a text DSV data file specified in the repetition command, or
- One repetition for each value in a DSV list, which itself could be a field value in a DSV data file, or
- Initialization of a specified TemplaGen variable that is then incremented for each repetition, or
- Repetition until a condition occurs
Note that, in a repetition with an incrementing TemplaGen variable, that variable could be used to subscript through an associative array. - Each template line can contain multiple data insertion commands (or
none). Each such command allows insertion of a data value drawn
from all current DSV data sources, associative arrays,
environment variables, and TemplaGen
variables, with the following optional editing
options:
- Default value to apply if a DSV data field has no value in the current data line.
- Use of a DSV expression to create the inserted value; such an expression can reference any current field from any DSV data source currently being used, as well as associative arrays and environment and TemplaGen variable values. This allows sophisticated data transformations involving multiple data sources.
- Forcing of the inserted value to lower or upper case.
- Insertion of commas (or, for European style, periods) into numbers.
- User-specified character string replacements to apply to the
inserted value before other editing, including the optional use of regular
expressions (pattern matching) with
(...)groups. - Special character escaping for a variety of computer languages (including XTRAN's rules language!), allowing values to be inserted into multiple language contexts.
- Text prefix and/or suffix to be applied to an inserted value, before or after justification and fill.
- Prefix and/or suffix output lines to be applied to the template line containing the data insertion command.
- Minimum value width, with fill using a specified (or defaulted) fill character.
- Left, right, or centered justification within that minimum width if needed.
- Maximum width, to which the inserted value will be truncated if needed, after all editing (if any) has been applied, with optional truncation indicators.
- It allows the use of included files of
TemplaGen commands and template
lines, optionally specifying that such a file uses a different comment
character than the file that includes it. Such a file might
contain:
- Commonly used data source, string replacement, and field value editing commands.
- "Boilerplate" text that must appear in multiple artifacts.
- Whole template sections that are common to multiple artifacts, e.g. headers and footers.
- TemplaGen commands to load a set of associative arrays with the contents of an external data base, for use by a template, which needs only to include the file. (Example 8, below, uses this technique.)
One application of this capability is to implement HTML include files with no scripting. In fact, we use that TemplaGen feature on this very Web site to handle its Web page headers and footers, as well as other repeated chunks of HTML.
These capabilities allow TemplaGen to automatically generate a variety of artifacts from data repositories. A change in repository data can then trigger automatic regeneration of those artifacts, ensuring that they all remain synchronized and up to date.
A typical DevOps scenario would create procedures so that, whenever there is a change in repository data, the relevant data are automatically exported from the repository in DSV form and TemplaGen is run to regenerate all artifacts affected by the change in the repository data — code, documentation, reports, DevOps scripts, etc.
Note that, by specifying different conditionalization and the use of different data fields and field value editing in different TemplaGen runs, we can generate a wide variety of artifacts from the same data source. For instance, the first four examples below use the same data file to generate dramatically different artifacts.
How can such powerful and generalized template-driven artifact generation from data be automated in less than 5,000 code lines of XTRAN rules? Because there is so much capability already available as part of XTRAN's rules language (in which TemplaGen is implemented). TemplaGen's rules take advantage of the following XTRAN functionality:
- Text file input and output
- Text manipulation
- Text formatting
- Delimited list manipulation, including DSV expressions
- Environment variable manipulation
- Regular expression (pattern) matching, with groups
- Content-addressable data bases
- "DSV expression" language, including associative arrays
- Language-specific special-character escaping
- Creating new meta-functions written in meta-code, which we call user meta-functions
- Meta-variable and meta-function pointers
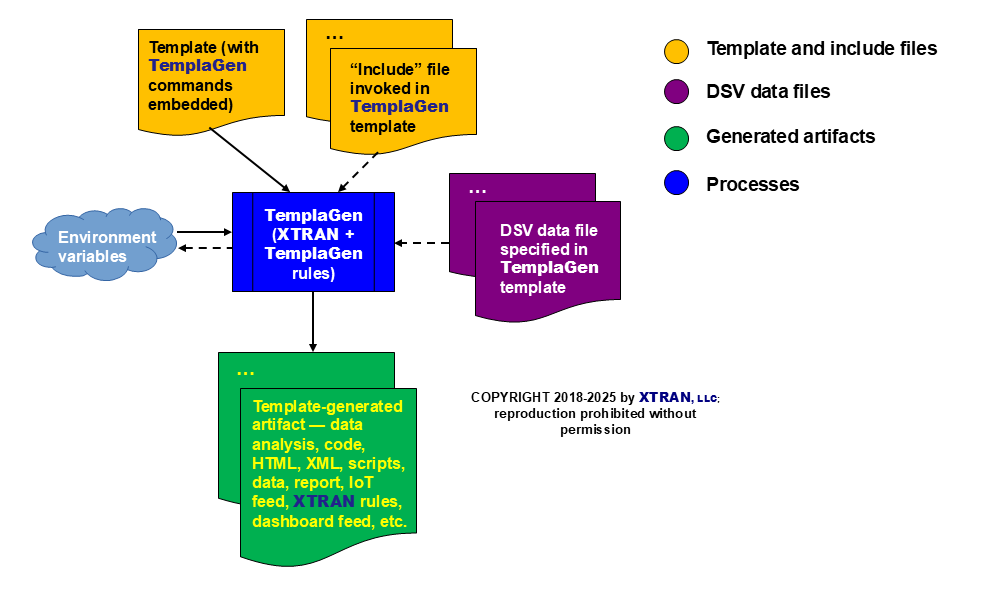
Process Flowchart
Here is a flowchart for TemplaGen:
Typical Use Cases
Scenario 1 — you are an election official looking for errors and potential fraud in the voter registration data you maintain for your jurisdiction, and analyzing voting results. (See Example 12 for a real-life example.)
Scenario 2 — you are an anti-terrorism analyst looking for common authorship between a terrorist's manifesto and a suspect's social media postings, or you are a publishing editor looking for plagiarism.
Scenario 3 — you are a candidate running for a political office, and you want to mail a flyer to a targeted subset of your potential constituents (See Example 13 for a real-life example.).
Scenario 4 — you are a Master Data Manager (MDM) in charge of a "single source of truth" enterprise data repository. Multiple artifacts (code, documentation, etc.) are individually generated from the data in that repository. So every time there are changes in the data, all of those artifacts must be painfully updated to reflect those changes — a laborious and error-prone process.
Scenario 5 — you are a data engineer, and you need to do sophisticated data transformations from and to multiple data sources, including cleanup, formatting, data selection, normalizing the data for input, and denormalizing the results. The first step is error-checking new data, to determine whether it has missing or illegal values that could interfere with your data analysis and transformation efforts. Then you're faced with the task of normalizing different data models, including data structures and ontology / taxonomy mismatches.
Scenario 6 — you are the Webmaster for a large and complex Web site, and you have two problems:
- Much of the site's contents come from a content repository, and you need to propagate those contents across the site.
- You would like to use an "include" facility to eliminate redundancy across the site, but you don't want to use scripting to do so because some of the site's users disable scripting in their browsers.
Scenario 7 — you are a software architect in a sizable development shop; your code is riddled with dependencies on data from your MDM's repository. Whenever the repository changes, your developers must manually update all of the code tables affected by the changes.
Scenario 8 — you are a DevOps engineer whose software environment includes many object libraries and executable programs, each requiring its own make file. Each time a library or executable program's object file list changes, you must modify its make file. This is error-prone, and over time leads to make files that are hard to read and maintain.
Scenario 9 — you are a Robotic Process Automation (RPA) engineer, prospecting for manual processes you can automate. To do so, you need to quickly and painlessly capture the business rules in the manual process in an automated and repeatable form.
Scenario 10 — you are a data scientist doing Big Data, Machine Learning, and Artificial Intelligence. You are wrestling with the mismatch between the data needs of those disciplines and all of the messy, unnormalized data out in the real world, with multiple, incompatible data sources. You are also dealing with very large data sets, perhaps terabytes or even petabytes, so your data wrangling solution needs to scale to handle such large data sets.
Scenario 11 — you are an XTRAN knowledge engineer, capturing software engineering expertise as XTRAN rules, and you notice that there is significant repetition of patterns in the XTRAN rules you are creating.
Scenario 12 — you are a software engineer charged with the task of maintaining, documenting, and testing an API for any of:
- A traditional 3GL function library
- A traditional EDI interface
- A set of object-oriented (OO) class methods
- A set of microservices
- A set of Web services
- A remote procedure call (RPC) interface
- JSON:API
You must maintain your API's implementation, user documentation, and testing, and keep all of them synchronized.
Scenario 13 — you are the TemplaGen librarian, in charge of maintaining your enterprise's TemplaGen templates. You want a BASH script that searches all of those templates, plus your TemplaGen "include" files, for a given text pattern (such as a TemplaGen command), and you want that script to be automatically updated whenever you create or delete a TemplaGen template or "include" file (very meta!).
TemplaGen to the rescue!
In-House Use at XTRAN, LLC
We use TemplaGen ourselves to automatically generate XTRAN code, documentation, and DevOps artifacts for the following XTRAN entities (among others):
- More than 450 meta-functions built into XTRAN's rules language, including their APIs, with over 30 different parameter descriptions.
- About 12 meta-function evaluation result data types.
- More than 40 computer languages XTRAN handles, with over 40 language dialects.
- More than 130 XTRAN command line flags, with over 30 different parameter descriptions and over a dozen types of action.
- More than 90 XTRAN state flags.
- More than 50 XTRAN commands.
- More than 70 XTRAN User's Manual chapters, combined to create about 30 Manual variants.
- More than 100 meta-debugger commands for debugging XTRAN's rules language, in 10 categories, with over 20 different parameter descriptions.
- About 20 events on which XTRAN's meta-debugger can break.
- More than 490 error codes.
- More than 160 internal code structures, and more than 90 included files that declare them.
- About a dozen XTRAN processing phases.
- Templates for HTML pages (documentation, Web site, etc.), with standardized headers and footers, and content that repeats for other entities in this list.
- Boilerplate text that TemplaGen can automatically format for different artifact types (code, documentation, etc.).
- More than 5,000 source files containing XTRAN's code, which comprises about 1 million code lines.
- More than 60 function libraries used to build XTRAN, including their APIs.
- 8 XTRAN build types, based on activities (analysis, re-engineering, different translation types, rules-only).
- More than 70 XTRAN executable builds, based on activities and languages.
- More than 40 XTRAN price brackets used to price XTRAN licenses, based on activity and lines of code.
- More than 85 TemplaGen templates used to create artifacts for these XTRAN entities (very meta!).
- These XTRAN entities (meta-meta!).
- Miscellaneous data coming in from customers.
All of those XTRAN entities and their instances reside in our XTRAN repository. From that repository, we use TemplaGen, with more than 60 templates, to automatically generate, for each entity, one or more of the following artifacts:
- C included files that provide compile-time information about the entities.
- C source code files that provide run-time information about the entities.
- HTML files that provide user and system documentation and Web content about the entities.
- "Make" files, for both subroutine libraries and executable programs.
- "Make" included files — included by the make files TemplaGen creates.
- Scripts to automate XTRAN builds.
- Scripts to automate other XTRAN DevOps tasks.
- Unit and regression test code for XTRAN's internal function libraries, based on their APIs.
- XTRAN rules for regression testing and demonstration of both built-in and user XTRAN meta-functions. (That's right, TemplaGen can generate XTRAN rules, of which it is itself composed!)
- Reference text files for use in scripts.
- Boilerplate text, formatted appropriately for different artifact types.
- Error reports on data from customers, showing missing and/or illegal values.
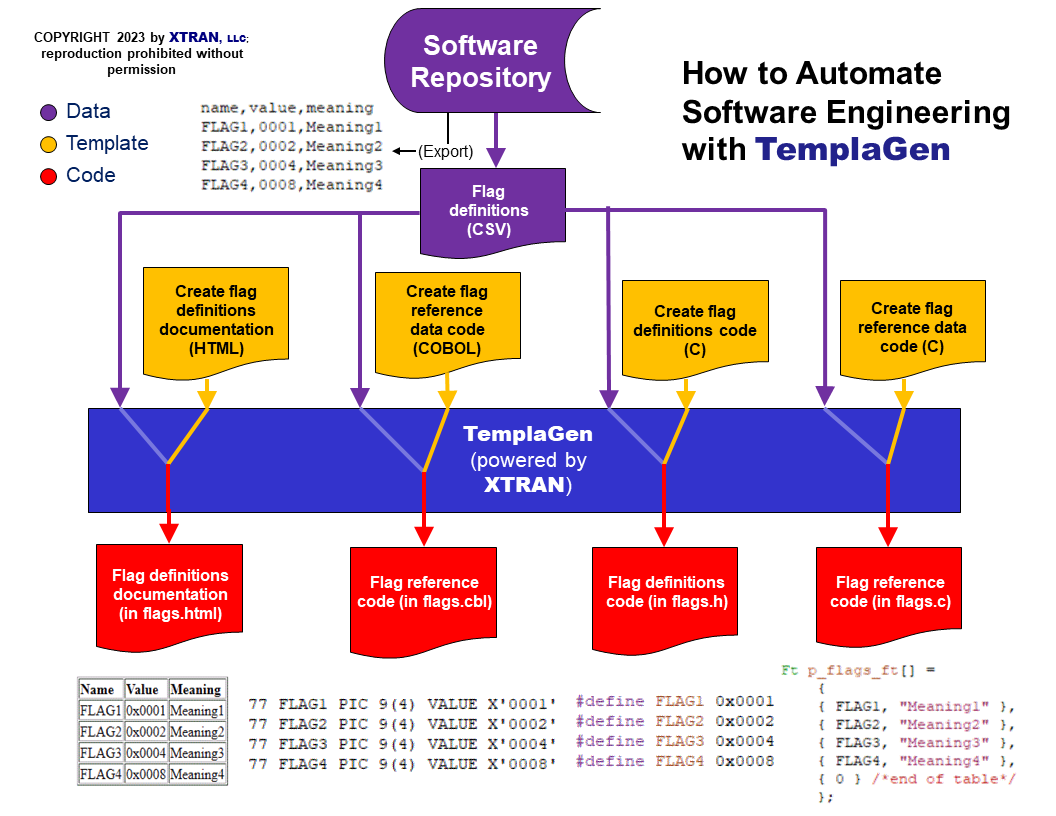
As an example of how we use TemplaGen for complex code generation, XTRAN has two central code files:
- An included file that defines system-wide codes, flags (including the state flags mentioned above), and quantities.
- A code module that contains system-wide tables and other information.
We generate both files with TemplaGen. The template for the included file uses data from the XTRAN repository for 6 of the entities above, and the template for the code module uses data for 8 entities. When the information for any of those entities changes, we push a button and both the included file and the code module are automatically recreated with refreshed information. The next time we build a version of XTRAN, it will automatically be up to date.
Since TemplaGen is written in XTRAN's rules language, XTRAN is actually automating itself!
And, since we also use TemplaGen to create both the XTRAN User's Manual and the TemplaGen User's Manual, TemplaGen is also automating itself!
In Example 7 below, you can see how we use TemplaGen to create "make" files for building XTRAN, from the contents of each library's source code directory.
In Example 9 below, you can see how we use TemplaGen editing capabilities to format block comments nicely when we generate production or test code from our XTRAN repository.
In Example 11 below, you can see how we use TemplaGen to create, from repository data, a script to search all of our templates for a text pattern (very meta!).
As an example of user-specified string replacements to be applied to a data field's value, when we use TemplaGen to generate XTRAN documentation from repository data, we specify the following string replacements for each data field whose value will be instantiated in a template as HTML non-markup text:
- Replace the string
XTRANwith<font class="xtr">XTRAN</font> - Replace the string
, LLCwith<font class="llc">, LLC</font>
The result, with a bit of help from a CSS style sheet, is that each
occurrence of the string XTRAN in such a data value will be
rendered in the generated HTML artifact as XTRAN, and
each occurrence of the string XTRAN, LLC will be rendered as
XTRAN, LLC.
The advantage of using TemplaGen's template-driven artifact automation capabilities to generate XTRAN production and test code, documentation, and DevOps artifacts is that, after any change to the XTRAN data repository, we run TemplaGen using scripts that automatically update all affected code, DevOps artifacts, and documentation, both external and internal. Each subsequent XTRAN build and test cycle will automatically incorporate all relevant code changes.
TemplaGen Examples
In the following examples, data processed by templates is shown first in spreadsheet form and then in the DSV form actually processed by TemplaGen. Typically the data will be exported from a repository.
Data file
The first four examples use the same data, from a function repository:
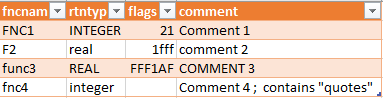
Exporting that results in the following TemplaGen data file:
! data1234.dsv -- data file for TemplaGen examples ! Exported 2019-03-01.1630 from our function repository ! ! Field labels: Function name, return type, flags, comment ! fncnam,rtntyp,flags,comment ! ! Data: ! FNC1,INTEGER,21,Comment 1 F2,real,1fff,comment 2 func3,REAL,FFF1AF,COMMENT 3 fnc4,integer,,Comment 4; contains "quotes" ! ! End of data file
Because this data file uses a comment character that's not the
default of ; (semicolon), in our template we specify
! as the data file's comment character. However, it uses the
default DSV data delimiter of , (comma), so we don't need
to specify that.
Each of the examples also assumes environment variables set to:
- The specification for each data file to be used. The environment variable value is then implied by each repetition command in the template that uses the named file's data. It can also be used in the instantiated results to identify the source of the data, and in error messages. This allows the same TemplaGen template to be used with different sets of data by simply changing environment variable settings in the script that is running TemplaGen.
- The date and time of the run, which are then plugged into each of the artifacts generated by TemplaGen. (We use a script to set them before running TemplaGen.)
For each example, the instantiated output file is shown.
Example 1 — Generate an HTML table
In the template for this example, we specify the following editing for each field it uses. For "Function name", it includes a group of two string replacements.
| Field description | Force case | Language | String originals |
String replacements |
|---|---|---|---|---|
| Function name | Lower | fnc1 func3 |
<i>fnc1</i> <b>func3</b> |
|
| Return type | Upper | |||
| Comment | HTML |
Instantiated target file, as HTML:
<html> <!-- Function return type table; automatically generated 2019-03-01 by TemplaGen from data1234.dsv --> <div> <table> <tr> <th><u>Function name </u></th> <th align="right"><u>Return result type</u></th> <th align="left"><u>Comment</u></th> </tr> <tr> <td><i>fnc1</i></td> <td align="right">INTEGER</td> <td>fnc1</td> <td>Comment 1</td> <tr> <tr> <td>f2</td> <td align="right">REAL</td> <td>comment 2</td> <tr> <tr> <td><b>func3</b></td> <td align="right">REAL</td> <td>COMMENT 3</td> <tr> <tr> <td>fnc4</td> <td align="right">INTEGER</td> <td>Comment 4; contains "quotes"</td> <tr> </table> </div> </html>
Instantiated target file, as rendered by this browser:
| Function name | Return result type | Comment |
|---|---|---|
| fnc1 | INTEGER | Comment 1 |
| f2 | REAL | comment 2 |
| func3 | REAL | COMMENT 3 |
| fnc4 | INTEGER | Comment 4; contains "quotes" |
Example 2 — Generate a C array of structures
In the template for this example, we specify the following editing for each field it uses:
| Field description | Force case | Prefix | Suffix | Min field width | Justification | Fill character | Language |
|---|---|---|---|---|---|---|---|
| Function name | ", |
10 | (defaulted to left) | (defaulted to <SPACE>) |
|||
| Flags | Upper | 8 | Right | 0 |
|||
| Comment | Lower | C |
Instantiated target file:
#include "stg.h"
/*
* Function flags table; automatically generated 2019-03-01
* by TemplaGen from data1234.dsv
*/
struct stg p_stg_table[] =
{
{ "FNC1", 0x00000021, "comment 1" },
{ "F2", 0x00001FFF, "comment 2" },
{ "func3", 0x00FFF1AF, "comment 3" },
{ "fnc4", 0x00000000, "comment 4; contains \"quotes\"" },
{ NULL } /*end of table*/
};
Note that, because data1.dsv's data line with fnc4
has no value for the "flags" field, TemplaGen
zero-filled that field to the minimum field width of 8.
This is a good example of TemplaGen's ability to automate the creation of well-styled, maintainable artifacts. The code above, far from being ugly and mechanical, is styled as well as if a human developer had coded it.
Example 3 — Generate a text document
In the template for this example, we specify the following editing for each field it uses:
| Field description | Force case | Min field width | Fill character |
|---|---|---|---|
| Function name | |||
| Return type | Upper | ||
| Flags | 1 |
0 |
|
| Comment | Lower |
Instantiated target file:
This document was automatically generated 2019-03-01 by TemplaGen from data1234.dsv, which was exported from our repository after changes in repository data. The function FNC1 has a return type of "INTEGER". Its flags are 0x21. Its comment is 'comment 1'. The function F2 has a return type of "REAL". Its flags are 0x1fff. Its comment is 'comment 2'. The function func3 has a return type of "REAL". Its flags are 0xFFF1AF. Its comment is 'comment 3'. The function fnc4 has a return type of "INTEGER". Its flags are 0x0. Its comment is 'comment 4; contains "quotes"'. For more information about this document, please contact our repository administrator.
Note that, because data1.dsv's data line with fnc4
has no value for the "flags" field, TemplaGen
zero-filled that field to the minimum field width of 1.
Example 4 — Data selection and transformation
This example is the same as Example 1, except that we use TemplaGen's conditionalization capabilities to select data based on criteria, and we use its data transformation capabilities to create new data forms from our DSV data. Both use DSV expressions, which reference the values of DSV field labels and environment variables.
In our template, we use a DSV expression to specify that only DSV
data lines whose rtntyp field has a value of REAL
(case-insensitive) are to cause instantiation.
We also use a DSV expression with regular expression (pattern) matching and
replacement to remove "comment " from the value of
the comment field, if it's there, and instantiate the result.
In the template for this example, we specify the following editing for each field it uses.
| Field description | Force case | Language | Transformation |
|---|---|---|---|
| Comment | Lower | HTML | Remove "comment " if there |
Instantiated target file, as HTML:
<html> <!-- "REAL" function return type table; automatically generated 2019-03-01 by TemplaGen from data1234.dsv --> <div> <table> <tr> <th><u>"REAL" function name </u></th> <th align="left"><u>Comment</u></th> </tr> <tr> <td>F2</td> <td>2</td> <tr> <tr> <td><b>func3</b></td> <td>3</td> <tr> </table> </div> </html>
Instantiated target file, as rendered by this browser:
| "REAL" function name | Comment |
|---|---|
| F2 | 2 |
| func3 | 3 |
Example 5 — Use regular expressions to embed HTML markup in normal text
In this example, we use regular expressions (text patterns, a.k.a. regexps) to embed HTML markup in normal text data, such that it survives when we're instantiating it as HTML non-markup text, but it's deleted when we're instantiating it as, e.g., a text literal in C code. To do that, we specify the same regexp for both scenarios, but with different replacement strings:
- For the HTML target case, we use a regexp
(...)group to specify that each occurrence of#...#is replaced with<...>. - For the C code target case, we use the same regexp group to specify that
each occurrence of
#...#is deleted.
(We use #...# for our embedded HTML markup instead of
<...> because we want TemplaGen to
"escape" characters in the rest of the text for HTML when that's what
we're generating, and <...> would then be
"escaped" to <...>.)
With that scheme in place, let's say we have a data field value in which we've embedded some HTML markup and some double quotes:
The #b#frammis#/b# will be "pulverized".
When we're generating HTML, our regexp match and replace plus character "escaping" for HTML will generate:
The <b>frammis</b> will be "pulverized".
…which will then be rendered as:
The frammis will be "pulverized".
But when we're generating C code and using our data field to generate a C text literal, surrounded in the template by double quotes, our regexp match and replace plus character "escaping" for C will generate:
"The frammis will be \"pulverized\"."
And when we're generating C code and using our data field to generate a C comment, our regexp match and replace will generate:
/*The frammis will be "pulverized".*/
Example 6 — Combine data from multiple sources
In this example, we use a template that draws on multiple data sources to create a C included file.
This example is an abbreviated form of what we actually do in real life. XTRAN, our Expert System in whose rules language TemplaGen is implemented, manipulates over 40 computer languages (as well as data and text). It also handles multiple dialects of some of those languages. The XTRAN repository contains a table of languages and a table of their dialects.
A more complicated instance, also from real life — in XTRAN's Internal Representation (XIR), each symbol that is declared and/or used in code content XTRAN parses is an instance of the "symbol" entity in our XTRAN repository. Because the C included file that declares that entity must also declare several ancillary structures, codes, and flags, the TemplaGen template that generates that included file uses a total of 7 DSV input data files exported from our XTRAN repository.
The C included file below, generated with TemplaGen, defines both the internal numbers that represent languages and the flags that represent their dialects.
This example's TemplaGen template specifies the following DSV data files, exported from the XTRAN repository and abbreviated for demonstration purposes:
Languages information
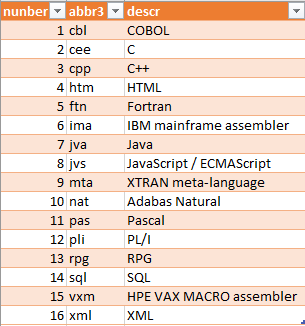
Exporting that results in the following TemplaGen data file:
; languages.dsv -- Languages info for TemplaGen demo ; Exported 2021-02-28.1722 from the XTRAN repository ; ; COPYRIGHT 1984-2025 by XTRAN, LLC; reproduction or use prohibited without ; permission. ; ; Label row: ; number~abbr3~descr ; ; Data: ; 1~cbl~COBOL 2~cee~C 3~cpp~C++ 4~htm~HTML 5~ftn~Fortran 6~ima~IBM mainframe assembler 7~jva~Java 8~jvs~JavaScript / ECMAScript 9~mta~XTRAN meta-language 10~nat~Adabas Natural 11~pas~Pascal 12~pli~PL/I 13~rpg~RPG 14~sql~SQL 15~vxm~HPE VAX MACRO assembler 16~xml~XML ; ; End of demo-mult-langs.dsv
Language dialects information
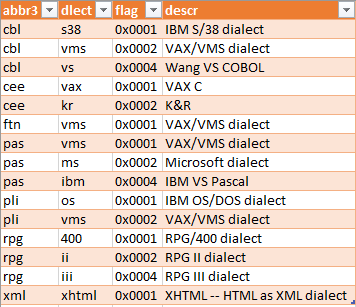
Exporting that results in the following TemplaGen data file:
; demo-mult-dlects.dsv -- Language dialects info for TemplaGen demo ; Exported 2019-09-24.1515 from the XTRAN repository ; ; COPYRIGHT 1984-2023 by XTRAN, LLC; reproduction or use prohibited without ; permission. ; ; Label row: ; abbr3~dlect~flag~descr ; ; Data: ; cbl~s38~0x0001~IBM S/38 dialect cbl~vms~0x0002~VAX/VMS dialect cbl~vs~0x0004~Wang VS COBOL cee~vax~0x0001~VAX C cee~kr~0x0002~K&R ftn~vms~0x0001~VAX/VMS dialect pas~vms~0x0001~VAX/VMS dialect pas~ms~0x0002~Microsoft dialect pas~ibm~0x0004~IBM VS Pascal pli~os~0x0001~IBM OS/DOS dialect pli~vms~0x0002~VAX/VMS dialect rpg~400~0x0001~RPG/400 dialect rpg~ii~0x0002~RPG II dialect rpg~iii~0x0004~RPG III dialect xml~xhtml~0x0001~XHTML -- HTML as XML dialect ; ; End of demo-mult-dlects.dsv
Resulting C included file
Here's the resulting C included file, created using TemplaGen:
/* demo-mult.h -- Demonstrate TemplaGen combining info from multiple sources * Created 2019-09-24.1520 by TemplaGen from XTRAN repository data * * COPYRIGHT 1984-2023 by XTRAN, LLC; reproduction or use prohibited without * permission. * * NOTE -- this file is automatically generated by TemplaGen (powered by * XTRAN); do not edit it! */ /* * The following are the numbers XTRAN uses to identify languages it handles, * plus their dialect flags. (Both sets are abbreviated for demo purposes.) */ #define CBL_NUM 1 /*COBOL*/ #define CBL_S38_F 0x0001 /* IBM S/38 dialect*/ #define CBL_VMS_F 0x0002 /* VAX/VMS dialect*/ #define CBL_VS_F 0x0004 /* Wang VS COBOL*/ #define CEE_NUM 2 /*C*/ #define CEE_VAX_F 0x0001 /* VAX C*/ #define CEE_KR_F 0x0002 /* K&R*/ #define CPP_NUM 3 /*C++*/ #define HTM_NUM 4 /*HTML*/ #define FTN_NUM 5 /*Fortran*/ #define FTN_VMS_F 0x0001 /* VAX/VMS dialect*/ #define IMA_NUM 6 /*IBM mainframe assembler*/ #define JVA_NUM 7 /*Java*/ #define JVS_NUM 8 /*JavaScript / ECMAScript*/ #define MTA_NUM 9 /*XTRAN meta-language*/ #define NAT_NUM 10 /*Adabas Natural*/ #define PAS_NUM 11 /*Pascal*/ #define PAS_VMS_F 0x0001 /* VAX/VMS dialect*/ #define PAS_MS_F 0x0002 /* Microsoft dialect*/ #define PAS_IBM_F 0x0004 /* IBM VS Pascal*/ #define PLI_NUM 12 /*PL/I*/ #define PLI_OS_F 0x0001 /* IBM OS/DOS dialect*/ #define PLI_VMS_F 0x0002 /* VAX/VMS dialect*/ #define RPG_NUM 13 /*RPG*/ #define RPG_400_F 0x0001 /* RPG/400 dialect*/ #define RPG_II_F 0x0002 /* RPG II dialect*/ #define RPG_III_F 0x0004 /* RPG III dialect*/ #define SQL_NUM 14 /*SQL*/ #define VXM_NUM 15 /*HPE VAX MACRO assembler*/ #define XML_NUM 16 /*XML*/ #define XML_XHTML_F 0x0001 /* XHTML -- HTML as XML dialect*/ /* End of demo-mult.h*/
Again, notice that the include file automatically generated using TemplaGen from repository data is styled as nicely as if it was written by a developer with good craftsmanship.
Example 7 — Generate "make" files for DevOps
In this example, we use a template that uses source code directory contents to create make files.
This example is an abbreviated form of what we actually do in real life. XTRAN, our Expert System in whose rules language TemplaGen is implemented, comprises more than 1 million code lines in more than 5,000 source code files, organized into more than 70 function libraries, to build more than 70 different executable versions. Each library and executable needs its own make file for use on Unix/Linux systems.
In our make files, we like to use "make" macros to specify the source code files that comprise each function library used in XTRAN, to keep the build commands readable. But we have found that some "make" utilities can't handle very large "make" macros. So, in our TemplaGen template, we state that we want the library's object files to be specified via multiple make file macros. We also specify the maximum number of object file names per macro, the maximum number of object file names per line in each macro, and the maximum number of macro names per line.
For this example, we specified the following, via environment variable settings in the script that runs TemplaGen:
- Libary's name:
demlib. Note that our template generated its abbreviation,DEML, from the name using a regular expression and case forcing. - Maximum number of object files per macro: 11
- Maximum number of object files per macro line: 3
- Maximum number of macro names per line: 4
This example uses an input DSV file with the following contents; it was created from the library's source file directory contents using a script. This means that if we create a new source file in that directory and rerun the script, the new source file will be automatically added to the make file the next time you use TemplaGen to create it. Similarly, if we delete a source file from the directory — or rename a source file — our make file is automatically updated the next time we create it.
; demmakelib.dsv -- Data for demonstrating TemplaGen make file generation ; ; COPYRIGHT 1984-2023 by XTRAN, LLC; reproduction or use prohibited without ; permission. ; ; Label row: ; srcename ; ; Object modules in this library: ; obj1 obj2 ... (elided for brevity) obj55 obj56 ; ; End of demmakelib.dsv
TemplaGen's output looks like this:
# make file -- for demlib library # Created 2020-09-14.1529 by TemplaGen per demlib's source files # # COPYRIGHT 1984-2023 by XTRAN, LLC; reproduction or use prohibited without # permission. # # NOTE -- This file is generated with TemplaGen (powered by XTRAN); DO NOT edit # it! # # Environment variable settings we require at "make" time: # # Envir var Setting # ---------------------------------------------------- # LIBDIR Path to directory containing library and its source files # DEML demlib library's full file spec # O File type to use for an object file, e.g. .obj or .o # # ***************************************************************************** # * Target definitions * # ***************************************************************************** # default: $(DEML) #default build # clean: #clean library project rm -f $(LIBDIR)/*.$(O) $(DEML) # list: #list objects in library ar t $(DEML) >$(LIBDIR)/demlib.lis # # ***************************************************************************** # * demlib * # ***************************************************************************** # # Note: We use multiple numbered macros to specify the object modules for our # library because some "make" utilities can't handle very large macro # definitions. E.g., AIXV4's "make" failed with no error message. # OBJECTS1 = \ $(DEML)(obj1.$(O)) $(DEML)(obj2.$(O)) $(DEML)(obj3.$(O)) \ $(DEML)(obj4.$(O)) $(DEML)(obj5.$(O)) $(DEML)(obj6.$(O)) \ $(DEML)(obj7.$(O)) $(DEML)(obj8.$(O)) $(DEML)(obj9.$(O)) \ $(DEML)(obj10.$(O)) $(DEML)(obj11.$(O)) OBJECTS2 = \ $(DEML)(obj12.$(O)) $(DEML)(obj13.$(O)) $(DEML)(obj14.$(O)) \ $(DEML)(obj15.$(O)) $(DEML)(obj16.$(O)) $(DEML)(obj17.$(O)) \ $(DEML)(obj18.$(O)) $(DEML)(obj19.$(O)) $(DEML)(obj20.$(O)) \ $(DEML)(obj21.$(O)) $(DEML)(obj22.$(O)) OBJECTS3 = \ $(DEML)(obj23.$(O)) $(DEML)(obj24.$(O)) $(DEML)(obj25.$(O)) \ $(DEML)(obj26.$(O)) $(DEML)(obj27.$(O)) $(DEML)(obj28.$(O)) \ $(DEML)(obj29.$(O)) $(DEML)(obj30.$(O)) $(DEML)(obj31.$(O)) \ $(DEML)(obj32.$(O)) $(DEML)(obj33.$(O)) OBJECTS4 = \ $(DEML)(obj34.$(O)) $(DEML)(obj35.$(O)) $(DEML)(obj36.$(O)) \ $(DEML)(obj37.$(O)) $(DEML)(obj38.$(O)) $(DEML)(obj39.$(O)) \ $(DEML)(obj40.$(O)) $(DEML)(obj41.$(O)) $(DEML)(obj42.$(O)) \ $(DEML)(obj43.$(O)) $(DEML)(obj44.$(O)) OBJECTS5 = \ $(DEML)(obj45.$(O)) $(DEML)(obj46.$(O)) $(DEML)(obj47.$(O)) \ $(DEML)(obj48.$(O)) $(DEML)(obj49.$(O)) $(DEML)(obj50.$(O)) \ $(DEML)(obj51.$(O)) $(DEML)(obj52.$(O)) $(DEML)(obj53.$(O)) \ $(DEML)(obj54.$(O)) $(DEML)(obj55.$(O)) OBJECTS6 = \ $(DEML)(obj56.$(O)) # # Make our library: # $(DEML): \ $(OBJECTS1) $(OBJECTS2) $(OBJECTS3) $(OBJECTS4) \ $(OBJECTS5) $(OBJECTS6) # @echo demlib is made. # # End of make file for demlib
Example 8 — Generate multiple artifacts from multiple data sources
For this example, we use a TemplaGen template that uses a customer data repository, which it reads from a DSV data file and stores in an associative array, to process customer invoice data.
The template took only 3 hours to create and debug.
For each invoice:
- It checks whether the customer is approved for credit.
- If so, it checks whether the invoice amount exceeds the customer's "per invoice" limit.
The template generates two artifacts:
- An error log of invalid invoices, showing the reason for each invoice's rejection.
- A set of valid invoice data, excluding invalid invoices and reformatted from the original set — fields reordered, and the invoice amount formatted as currency.
Here's the customer repository data:
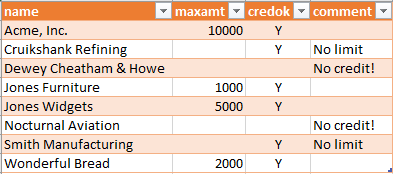
Exporting that results in the following TemplaGen data file:
; customers.dsv -- DSV customer data for demonstrating TemplaGen ; Exported 2021-02-28.1135 from the Customer Data Repository ; ; COPYRIGHT 2020-2023 by XTRAN, LLC; reproduction or use prohibited without ; permission. ; ; Label row: ; ; name Customer name ; maxamt Maximum allowed invoice amount if any; empty means no limit ; credok Credit OK? "Y" => yes; empty means no ; comment Comment (documentation only) ; name~maxamt~credok~comment ; ; Data: ; Acme, Inc.~10000~Y~ Cruikshank Refining~~Y~No limit Dewey Cheatham & Howe~~~No credit! Jones Furniture~1000~Y~ Jones Widgets~5000~Y~ Nocturnal Aviation~~~No credit! Smith Manufacturing~~Y~No limit Wonderful Bread~2000~Y~ ; ; End of customers.dsv
Here's the invoice data to be processed, extracted from the Customer Transaction Data Base:
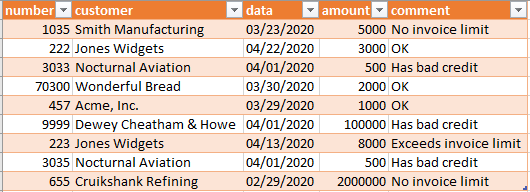
Exporting that results in the following TemplaGen data file:
; invoices.dsv -- DSV invoice data for demonstrating TemplaGen ; Exported 2021-02-28.1142 from the Customer Transaction Data Base ; ; COPYRIGHT 2020-2023 by XTRAN, LLC; reproduction or use prohibited without ; permission. ; ; Label row: ; number~customer~date~amount~amount ; ; Data: ; 1035~Smith Manufacturing~03/23/2020~5000~No invoice limit 222~Jones Widgets~04/22/2020~3000~OK 3033~Nocturnal Aviation~04/01/2020~500~Has bad credit 70300~Wonderful Bread~03/30/2020~2000~OK 457~Acme, Inc.~03/29/2020~1000~OK 9999~Dewey Cheatham & Howe~04/01/2020~100000~Has bad credit 223~Jones Widgets~04/13/2020~8000~Exceeds invoice limit 3035~Nocturnal Aviation~04/01/2020~500~Has bad credit 655~Cruikshank Refining~02/29/2020~2000000~No invoice limit ; ; End of invoices.dsv
When we run TemplaGen with our template, it generates the following error log:
Invoices Error Log
Created 2020-05-20 at 14:17 using TemplaGen for demdb-invoices.dsv
Customer Invoice # Amount Error
-------------------------------------------------------------------------------
Jones Widgets 222 $3,000 Violates maximum invoice amount
Nocturnal Aviation 3033 $500 Credit not approved
Acme, Inc. 457 $1,000 Violates maximum invoice amount
Dewey Cheatham & Howe 9999 $100,000 Credit not approved
Nocturnal Aviation 3035 $500 Credit not approved
End of error log
Here's the processed invoice data file our TemplaGen template created, with the fields reordered and the invoice amount reformatted:
; invoices.dsv -- Validated and processed Invoice data ; Created 2020-05-20 at 14:17 using Templagen from raw invoice data ; ; Field labels: ; customer~number~amt~date ; Acme, Inc.~01/13/2020~456~$10,000 Smith Manufacturing~03/23/2020~1035~$5,000 Wonderful Bread~03/30/2020~70300~$2,000 Jones Widgets~04/13/2020~223~$8,000 Cruikshank Refining~02/29/2020~655~$2,000,000 Jones Furniture~12/29/2019~2122~$1,000 ; ; End of processed invoices.dsv
Example 9 — Format block comments in generated code
In Example 2 we saw how we can use TemplaGen to generate computer code. In In-House Use, we described how, here at XTRAN, LLC, we use TemplaGen to generate C code for XTRAN, our Expert System in whose rules language TemplaGen is written. (That's right, XTRAN is automating itself!) We do so from content stored in our XTRAN repository in Relational Data Base (RDB) form, including both multi-line block comments and on-line comments.
In In-House Use, we also mentioned that we use TemplaGen to generate XTRAN rules to test and demonstrate XTRAN meta-functions, from information about them in the XTRAN repository. (That's XTRAN automating itself at the next level up!)
When we use TemplaGen to generate code or XTRAN rules, we want to format block comments nicely. TemplaGen's powerful editing capabilities allow us to do so.
For this example, we will use the following two-line block comment:
This is a two-line<NL>block comment.
The <NL> represents an embedded "newline"
character that, when instantiated by TemplaGen in our
code artifact, will break to the next line.
Here is that comment, from a code repository, formatted for various computer languages and styles using TemplaGen editing commands:
| Target languages | Formatted block comment |
|---|---|
| Pascal | {This is a two-lineblock comment.} |
| C++ Java C# SRL |
//// This is a two-line// block comment.// |
| C C++ Java C# PL/I |
/* * This is a two-line * block comment. */ |
| An assembler | ;; This is a two-line; block comment.; |
| HTML XML |
<!-- -- This is a two-line -- block comment. --> |
| C C++ Java C# PL/I |
/************************//* This is a two-line *//* block comment. *//************************/ |
| C++ Java C# SRL |
// ************************// * This is a two-line *// * block comment. *// ************************ |
| HTML XML |
<!--************************* This is a two-line ** block comment. ************************* |
We use the "framed" style you see in the last three cases for comments that introduce major code sections. The frames in this example are narrowed for demonstration purposes; in real life, they are 79 characters wide.
Example 10 — Look for common authorship based on interesting words and phrases
In this example, we use a TemplaGen template that inputs and stores a file of uninteresting words (a, and, the, etc.) to ignore, then analyzes unstructured text (emails, social media or blog postings, manifestos, editorials, speech transcripts, etc.) for occurrences of interesting words and phrases that use them.
The template allows us to specify the phrase size (2+ words).
It also treats lines starting with ; as comments.
Similarly, if you are looking for plagiarism, this analysis can point you to likely indicators, for more rigorous analysis.
The TemplaGen template we used consists of less than 150 non-comment lines.
Uninteresting words file
; ignore.dsv -- Uninteresting words to ignore for TemplaGen demo ; Revised 2020-09-28.2238 by Stephen F. Heffner (Win10 on PREC7520) ; ; COPYRIGHT 2020-2023 by XTRAN, LLC; reproduction or use prohibited without ; permission. ; a and but few for has have how in is it me my now of or over that the them this to we will with ; ; End of ignore.dsv
Text file to analyze
; input.txt -- Unstructured text for word and phrase analysis ; Revised 2020-09-21.1756 by Stephen F. Heffner (Win10 on PREC7520) ; ; COPYRIGHT 2020-2023 by XTRAN, LLC; reproduction or use prohibited without ; permission. ; This is a sample of prose we will process with XTRAN rules. It spans a number of lines, and has a few interesting words and phrases in it for the rules to analyze. The quick brown fox jumped over the lazy dog. I regret that I have but one life to give for my country. Give me liberty or give me death. A penny saved is a penny earned. Now we will repeat a few phrases to show how the XTRAN rules tally them. A penny saved is a penny earned. I regret that I have but one life to give for my country. A penny not saved is a penny wasted. The lazy dog woke up and chased the quick brown fox away. I regret that I have but one penny to give to charity, but a penny is better than nothing. ; ; End of input.txt
Word tallies file produced
; words.dsv -- Significant word tallies ; Created October 5, 2020 at 1:12 pm with TemplaGen (powered by XTRAN) ; ; Text to analyze: input.txt ; Words to ignore: ignore.dsv ; Punctuation: " \t,;.?!'\"" ; sample,1 prose,1 process,1 xtran,2 rules,3 spans,1 number,1 lines,1 interesting,1 words,1 phrases,2 analyze,1 quick,2 brown,2 fox,2 jumped,1 lazy,2 dog,2 i,6 regret,3 one,3 life,2 give,5 country,2 liberty,1 death,1 penny,8 saved,3 earned,2 repeat,1 show,1 tally,1 not,1 wasted,1 woke,1 up,1 chased,1 away,1 charity,1 better,1 than,1 nothing,1 ; ; End of words.dsv
Phrase tallies file produced
; phrases.dsv -- Phrase tallies ; Created October 5, 2020 at 1:12 pm with TemplaGen (powered by XTRAN) ; ; Text to analyze: input.txt ; Words to ignore: ignore.dsv ; Punctuation: " \t,;.?!'\"" ; Phrase length: 3 ; sample prose process,1 prose process xtran,1 process xtran rules,1 xtran rules spans,1 rules spans number,1 spans number lines,1 number lines interesting,1 lines interesting words,1 interesting words phrases,1 words phrases rules,1 phrases rules analyze,1 rules analyze quick,1 analyze quick brown,1 quick brown fox,2 brown fox jumped,1 fox jumped lazy,1 jumped lazy dog,1 lazy dog i,1 dog i regret,1 i regret i,3 regret i one,3 i one life,2 one life give,2 life give country,2 give country give,1 country give liberty,1 give liberty give,1 liberty give death,1 give death penny,1 death penny saved,1 penny saved penny,2 saved penny earned,2 penny earned repeat,1 earned repeat phrases,1 repeat phrases show,1 phrases show xtran,1 show xtran rules,1 xtran rules tally,1 rules tally penny,1 tally penny saved,1 penny earned i,1 earned i regret,1 give country penny,1 country penny not,1 penny not saved,1 not saved penny,1 saved penny wasted,1 penny wasted lazy,1 wasted lazy dog,1 lazy dog woke,1 dog woke up,1 woke up chased,1 up chased quick,1 chased quick brown,1 brown fox away,1 fox away i,1 away i regret,1 i one penny,1 one penny give,1 penny give charity,1 give charity penny,1 charity penny better,1 penny better than,1 ; ; End of phrases.dsv
Example 11 — Create BASH script to search all TemplaGen templates for a text pattern
In this example, we use a TemplaGen template that uses repository data to create a BASH script to search all of our TemplaGen templates for a text pattern. When we run the script, we can specify a pattern and a result file to receive the results of the search. It uses the popular grep utility; "grep" stands for "General Regular Expression Pattern search". The same approach can be used to generate any scripting language on any platform.
Our TemplaGen template consists of
less than 50 non-comment lines, and took less than 45
minutes to create and debug. It assumes that all of
our TemplaGen templates are
named <name>.tpl, and all of our
TemplaGen "include" files are named
<name>.tpi.
Here at XTRAN, LLC, we use this in real life to manage more than 80 in-house templates. This means that when we create a new template, rename an existing one, or delete one, we just update the repository, export the data, and run TemplaGen to create an up-to-date version of our script.
Repository data about TemplaGen templates
| dir | file | incl | tgt-dir | tgt-name | tgt-type | descr |
|---|---|---|---|---|---|---|
tpl |
invoice-incl |
Y |
TemplaGen include file for invoice-related templates |
|||
tpl |
po-incl |
Y |
TemplaGen include file for purchase-order-related templates |
|||
invoice/tpl |
invoice-rpt |
invoice/reports |
invoice-report |
txt |
Report of outstanding invoices |
|
po/tpl |
po-rpt |
po/reports |
po-report |
txt |
Report of outstanding purchase orders |
|
When we export that from our repository, we get the following DSV file:
; templates.dsv -- TemplaGen templates info ; Exported 2020-12-12.1532 from the enterprise repository ; dir,file,incl,tgt-dir,tgt-name,tgt-type,descr ; tpl,invoice-incl,Y,,,,Include file for invoice-related templates tpl,po-incl,Y,,,,Include file for purchase-order-related templates invoice/tpl,invoice-rpt,,invoice/reports,invoice-report,txt,Report of outstanding invoices po/tpl,po-rpt,,po/reports,po-report,txt,Report of outstanding purchase orders ; ; End of templates.dsv
Output from TemplaGen
When we run TemplaGen using our template and the DSV data we exported from our repository, we get:
# grep-tpl.bash -- Search all TemplaGen templates with a regular expression
# Created 2020-12-11.2306 by TemplaGen (powered by XTRAN)
#
# COPYRIGHT 2020-2023 by XTRAN, LLC; reproduction or use prohibited without
# permission.
#
# NOTE -- This script is generated with TemplaGen from the repository; DO NOT
# EDIT!
#
# Usage:
# $ grep-tpl.bash "<regexp>" "<outspc>"
# where:
# <regexp> = regular expression to search for
# <outspc> = output file spec
#
# Fetch our arguments:
#
GREP_RGX="$1" #get regexp to srch for
if [ "${GREP_RGX}" == "" ]; then #must have one
echo "?No regular expression given!" #gripe
exit 1 #fail
fi
#
GREP_OUT="$2" #get rslt file spec
if [ "${GREP_OUT}" == "" ]; then #must have one
echo "?No output file spec given!" #gripe
exit 1 #fail
fi
#
rm -f ${GREP_OUT} #delete existing rslts if any
#
grep -H "${GREP_RGX}" tpl/invoice-incl.tpi >>${GREP_OUT}
grep -H "${GREP_RGX}" tpl/po-incl.tpi >>${GREP_OUT}
grep -H "${GREP_RGX}" invoice/tpl/invoice-rpt.tpl >>${GREP_OUT}
grep -H "${GREP_RGX}" po/tpl/po-rpt.tpl >>${GREP_OUT}
#
echo "Done."
#
# End of grep-tpl.bash
Example 12 — Error-check DSV data
In this example, we use a TemplaGen template to error-check DSV data we have received from outside the shop, before submitting it to analysis and transformation efforts automated using TemplaGen. The template can be quickly set up to error-check any DSV data. The template comprises only 80 template lines! We created it in about three hours.
Our template reads in a set of error-checking criteria (as DSV data),
one criterion per line (ignoring lines starting with ; as
comments). Each criterion must take one of the following forms:
<fldlbl>,E,,<message> |
Field must have a value |
<fldlbl>,T,<type>,<message> |
Field must have the specified data type |
<fldlbl>,L,<value>,<message> |
Field's value must not be lower than <value> |
<fldlbl>,H,<value>,<message> |
Field's value must not be higher than <value> |
<fldlbl>,U,,<message> |
Field value must be unique |
where:
<fldlbl> |
The field label of the field to be checked in each DSV data row |
<type> |
The field's required data type — I for
integer, F for floating point, or T for text (the
default) |
<value> |
The low or high value for the L or H
error check |
<message> |
The message to show for each failure of this error check |
If any error check fails for a given field, the error is reported in the log and the subsequent checks of that field are not performed.
An environment variable must be set to identify the field label the template is to use when reporting each error's data row; this is normally the label of the field whose value is unique in each data record.
For instance, suppose you are an election official responsible for maintaining a jurisdiction's voter registrations. You might use error-checking criteria like this:
registrant ID,E,,No registrant ID registrant ID,U,,Duplicate registrant ID birth year,E,,No year of birth birth year,T,I,Birth year not integer birth year,L,2002,Too young to vote birth year,H,1920,100+ years old
We actually use this in real life, to help keep voter registration data clean. Setting up the error-checking criteria for each county takes just a few minutes; we maintain them in a spreadsheet workbook, with one worksheet for each county, and export them after any change. We run the template on each county's thousands (or in some cases millions) of voter registration records, using the appropriate error-checking criteria for that county. We have found a one-year-old baby registered to vote, many centenarians as old as 109 years, and people with no residence address.
Example 13 — Select Data Using Sophisticated Criteria
In this real-life example, we used a TemplaGen template to select voters from a county's registered voters roll, in order to help a political candidate do a mailing to selected potential constituents, using each selected voter's mailing address if any, else his/her residential address. The selection criteria the candidate wanted were as follows:
- Voter's status must be "active".
- Voter must reside in the candidate's precinct.
- Voter must reside in the targeted county.
- Voter must have voted in either the 2016 or the 2018 primary election for the candidate's party.
We created the template in about 45 minutes, ran it on the appropriate county's voter roll (about 35,000 registered voters), and delivered the list to the candidate in exactly the format needed by the printing company he had selected. He simply forwarded the list to the printing company, and they did the mailing.
Example 14 — Continue an Interrupted TemplaGen Run
Let's say you are using TemplaGen to analyze a very large data set comprising a million records, and the run is accidentally interrupted. Before the interruption, the run produced results for the first 400,000 data records. Can you continue the interrupted run starting with the 400,001th record, avoiding the need to rerun the analysis of the first 400,000 records?
Yes! TemplaGen has two features that enable you to do that:
- You can tell TemplaGen to skip the first n data records in the input file.
- You can tell TemplaGen to append its output to your analysis results file, instead of creating that file.
Of course, this assumes that your analysis doesn't involve computations across the entire data set, such as average values.
We actually used this capability in real life. We were error-checking a large county's registered voters list when the run was accidentally terminated part-way through. We simply told TemplaGen to start with the first unchecked record and to append the results to the existing error report.