XTRAN Example — Tally Tokens in a Text File
Scenario 1 — you have been given a file extracted from your A/R system, with customer country for each invoice in a given date range. You need to know how many sales were made to each country.
Scenario 2 — you have mined SQL code for CREATE
TABLE statements, and you've exported the table names to a
text file, one table name per line. There are many
duplications, and you need to know how many creations there are
of each table name in the SQL code. (This actually happened.)
XTRAN to the rescue!
The following example uses an XTRAN rules file comprising 85 non-comment lines of XTRAN's rules language ("meta-code") to tally tokens in a text file. The rules took less than 30 minutes to write and debug. (That's right, only ½ hour total!)
You can specify the input file to tally and the output file to create via environment variables, so it's easy to script into your workflow.
You can also document your data file with comments, specifying or defaulting the comment character to use.
You can also specify whether the tallying is to be done case-sensitively (the default is case-insensitive).
The rules use literally a single meta-statement to do the actual tallying of the text tokens in your input file.
How can such a powerful and generalized solution be automated in less than ½ hour and only 85 code lines of XTRAN rules? Because there is so much capability already available as part of XTRAN's rules language. These particular rules take advantage of the following functionality:
- Text file input and output
- Text manipulation
- Text formatting
- Delimited list manipulation
- Environment variable manipulation
- Content-addressable data bases (associative arrays)
The input to and output from XTRAN are untouched.
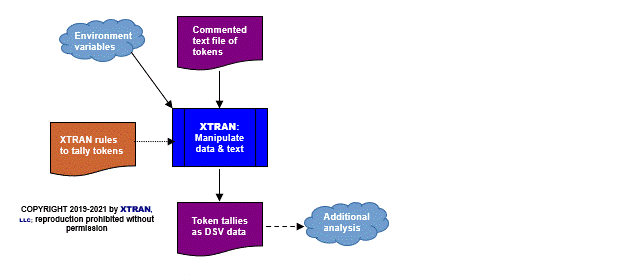
Process Flowchart
Here is a flowchart for this process, in which the elements are color coded:
- BLUE for XTRAN versions (runnable programs)
- ORANGE for XTRAN rules (text files)
- PURPLE for text data files
Input to XTRAN:
? tokens.dsv -- Tokens to tally ? apple orange banana apple banana apple orange kiwi banana banana ? ? End of tokens.dsv
Output from XTRAN:
apple,3 banana,4 kiwi,1 orange,2